

LLM-GUARD:基于大模型的C++和Python錯誤和安全漏洞的檢測和修復
責編:gltian |2025-08-29 14:40:01基本信息
原文標題:LLM-GUARD: Large Language Model-Based Detection and Repair of Bugs and Security Vulnerabilities in C++ and Python
原文作者:Akshay Mhatre, Noujoud Nader, Patrick Diehl, Deepti Gupta
作者單位:
- 德克薩斯農工大學中部校區計算機信息系統系
- 路易斯安那州立大學超級計算與技術中心
- 路易斯安那州立大學物理與天文學系
- 洛斯阿拉莫斯國家實驗室應用計算科學(CCS-7)
關鍵詞:人工智能(AI)、大語言模型(LLMs)、代碼審查、軟件開發、安全性、漏洞檢測、自動調試、C++、Python
原文鏈接:https://arxiv.org/pdf/2508.16419
開源代碼:https://github.com/NoujoudNader/LLM-Bugs-Detection
論文要點
論文簡介:本文針對當前大語言模型(LLMs)在代碼審查與自動調試中的角色持續提升,但其在自動檢測及修復C++和Python領域真實軟件缺陷、特別是安全相關高級漏洞方面的實證能力尚未得到充分研究。作者以ChatGPT-4、Claude 3與LLaMA 4三種主流模型為對象,基于包含基礎編程錯誤、典型安全漏洞及生產級高級Bug的綜合公開數據集,系統評測了它們在多類型C++與Python代碼缺陷上的表現。數據集涵蓋了SEED Labs、OpenSSL(Suresoft GLaDOS)、PyBugHive等來源,均經本地編譯與測試驗證。
作者設計了多階段、上下文感知的提示流程,真實模擬開發者調試場景,并采用分級評分表嚴格量化檢測的準確性、推理深度及修復建議質量。實驗顯示,所有模型均能較好識別基礎語法與語義錯誤,適合初學者教育和自動化代碼初審,但在高級安全漏洞與復雜生產環境代碼上的表現顯著下滑。ChatGPT-4與Claude 3相較LLaMA 4能提供更細致的上下文分析。這一研究揭示了大語言模型在軟件安全領域的潛力與局限,并為其實際應用邊界提出了實證依據。
研究目的:當前LLMs已被廣泛整合進軟件開發流程,助力代碼生成、調試及自動審查工作。然而,學界與業界關于這些模型在面向現實世界復雜C++和Python項目中的多樣性缺陷,尤其是安全敏感漏洞的檢測和修復效能,仍存在較大未知。論文意在系統性、量化地檢驗主流LLMs的實際能力。具體目標為:通過構建兼具編程初學者常見錯誤、典型安全漏洞、真實開源項目高階缺陷的綜合數據集,對ChatGPT-4、Claude 3、LLaMA 4三款代表性模型進行多維度評測,驗證其在實際開發調試與安全審計中的有效性。同時,論文探索如何通過多輪、上下文增強提示設計,更真實地還原軟件調試流程,并以分級評分標準量化不同模型的能力差異,為模型實際落地使用、安全可靠性評估及未來改進提供基礎性實證支持。
研究貢獻:
- 構建并發布了涵蓋C++與Python語言、覆蓋編程基礎型錯誤、安全漏洞及生產級高級Bug的高質量公開基準數據集,所有樣本均經本地編譯和測試環節驗證,確保問題的真實性和多樣性。
- 設計并實現了新穎的多階段、上下文感知型提示協議,真實模擬開發者實際調試和修復Bug的交互流程,為更科學合理地評價LLMs能力奠定基礎。
- 對ChatGPT-4、Claude 3、LLaMA 4三款前沿大語言模型進行了系統對比、細粒度分析,統一基于嚴格分級評分標準量化其在Bug檢測準確性、推理深度與修復建議等方面的表現,揭示了其優勢、短板及實際適用場景,為大模型在代碼質量保障領域的應用邊界與未來改進提供實證參考。
引言
隨著大語言模型(LLMs)在自然語言理解與生成領域的突破,諸如ChatGPT、Claude、GitHub Copilot、LLaMA和BERT等模型迅速成為軟件開發場景中的主流工具。這些模型不僅能夠將自然語言指令轉換為代碼,還能支持調試、自動答疑等各類代碼相關任務,在集成開發環境(IDE)、教育平臺和企業級DevOps流水線中被廣泛應用,極大地提升了開發效率,降低了新手入門門檻。
盡管LLMs在助力代碼生成和編程教育方面的潛能不斷釋放,學界和業界對于其在真實軟件開發中的可靠性、特別是針對復雜、多樣軟件缺陷和安全漏洞檢測能力的研究卻相對滯后。而這一空白具有重大現實意義:未被檢測的Bug會導致功能故障、安全漏洞,甚至給現代軟件系統帶來高昂的維護和安全風險。
本研究正是針對上述關鍵問題展開,提出全面、實證性的評測框架,專門分析ChatGPT-4、Claude 3(Sonnet 3.7)與LLaMA 4(maverick)等主流LLM在檢測與分析各類C++與Python真實Bug方面的表現,覆蓋從基礎編程失誤、經典安全漏洞到生產級項目中的高級缺陷。為確保嚴謹性,論文所用數據集包括SEED Labs與OpenSSL(通過Suresoft GLaDOS數據庫)中的C++示例、以及PyBugHive收集的Python典型Bug,均經過本地編譯測試驗證。這些樣本不僅反映了實驗室場景下的易錯點,還直接鏈接到實際生產環境下的高復雜度缺陷。
與以往僅依賴合成或窄范圍樣例的研究不同,作者的實驗體系強調真實Bug驗證,并通過多階段、上下文感知的提示對LLMs進行多輪交互,最大程度還原真實開發者定位調試流程。同時,針對Bug檢測的不同層次(如表層語法錯誤、深層語義漏洞與安全隱患),采用分級評分標準全面量化模型的檢測準確率、推理深度及修復建議合理性。這種多維度評測方法,有助于揭示LLMs在靜態和動態代碼分析上的優劣勢與適用邊界。
該工作的新穎性在于首次提出多層次、情境感知的LLM能力評估框架,從表淺語法到深度語義、再到安全級別漏洞全方位檢驗,填補了從純理論到實際工程領域的關鍵落差。與此同時,論文還關注了LLMs在自動化代碼審查、教育輔助、甚至安全審計領域的應用前景,并系統揭示其局限性,為后續研究提供了路徑和方法論。
相關工作與研究背景
近年來,利用大語言模型進行代碼缺陷與安全漏洞檢測已成為軟件工程與安全社區的研究熱點。已有工作探索了多種LLM及其衍生產品在多語言下的漏洞識別效能。例如,CodeQwen1.5、DeepSeek-Coder、CodeGemma、StarCoder-2、CodeLlama等模型在Python、Java、JavaScript等多種主流編程語言中進行過全面的漏洞檢測能力比對;LProtector則將ChatGPT應用于C++代碼自動審查;FuncVul結合LLM與函數級代碼切塊,以提升C/C++中安全缺陷的檢測精準度。一些研究專門關注在實際開發社區如Stack Overflow上流傳的易漏安全風險,測試主流LLM對真實代碼片段的安全感知能力。此外,自動程序修復(APR)的研究也正借助LLM不斷深化,諸如RepairAgent實現基于多智能體的Bug定位與修復,SRepair則側重多函數復合型缺陷修復及成本效率提升。
盡管相關領域進展迅猛,現有研究大多面臨兩方面局限:一是多數評測樣例過于合成化、脫離實際項目,難以揭示LLM在真實大規模生產環境中的檢測與分析能力;二是缺乏對“深度推理+多輪交互”調試流程的模擬,難以評估模型在復雜場景下的推理、定位和修復真實力。另有文獻綜述系統梳理了LLM在代碼安全與自動修復中的既有成就與瓶頸,但對大規模、全場景、全流程性評測仍有待補全。相較于上述工作,本文首次提出基于本地驗證、生產級數據集和動態交互協議的全流程實證評測體系,具有現實可用性與方法創新的突出特點。
研究方法與評測流程
本研究制定了一套科學、嚴謹且具工程適用性的評測流程,全面檢驗三款主流LLM在多層級軟件缺陷上的檢測、推理與修復能力。
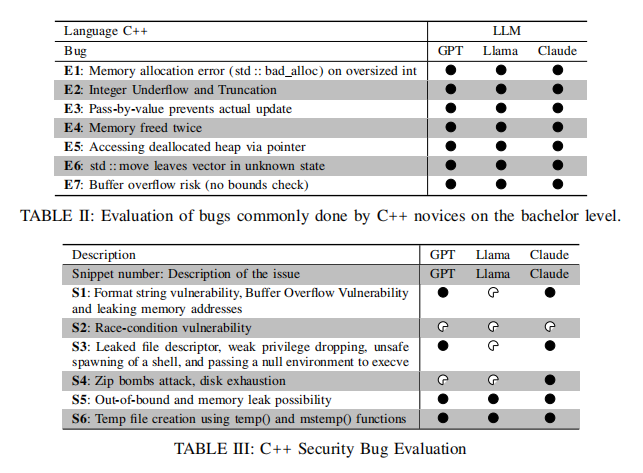
首先,論文構建了三大類數據集,覆蓋不同復雜度與語境的真實Bug。其一為基礎易錯型Bug,包括如未初始化變量、錯誤參數傳遞、內存管理失誤、邏輯漏洞、指針誤用等典型初學者失誤,主要來自大學編程課程常用教學案例。其二為C++安全漏洞樣本,包含經典的競態條件、格式化字符串漏洞、緩沖區溢出、不安全內存訪問與提權路徑等,突出安全紅線與攻擊面,由SEED Labs等安全教育平臺提供。其三為高級生產級Bug,具體拆分為OpenSSL(Suresoft-GLaDOS數據庫)內存安全、加密配置、類型推斷等復雜C/C++缺陷,以及PyBugHive中NumPy、Pandas等主流Python開源庫的API誤用、邊界行為、類型不匹配等代表性案例。每一項樣本均要求本地編譯(GCC 7.5/Python 3.7)或通過單元測試確認缺陷真實存在和可復現,保證原始數據質量與覆蓋面
在與LLM的交互設計上,論文推行“多階段上下文增強”提示機制。針對基礎Bug,設計了“請您列出以下代碼的所有編譯期、運行期、邏輯錯誤及漏洞,并指明相關行數”的標準化最小提示,以評測模型對孤立代碼的靜態檢測底線。對于高級Bug,進一步引入輔助上下文,如相關依賴文件片段、公共接口定義,模擬真實調試中開發者對周邊語義的整合推理。例如對NumPy特定函數,結合實際單元測試用例交互遞進,引導模型從現象到根因多步深入。這種動態、多回合提示策略不僅考查LLM的表層特征識別,更強調其跨文件、跨接口的上下文融合與推理適應能力。
在評估體系上,作者制定了分級可視化打分標準——從“未檢測到Bug”到“完全檢測并提出有效修復建議”分為五個檔次(空心圓至實心圓),嚴格統計每一模型在每類Bug、每輪交互下的表現,以量化模型準確率、推理深度與修復建議質量。這種設計兼顧了過程性、細粒度刻畫與最終效果輸出的統一,非常適合為自動化工具或安全審計場景提供決策參考。
各類型軟件缺陷檢測實驗與結果
全文對三類典型Bug的檢測能力差異做了細致、系統的實驗分析。
在基礎C++ Bug檢測方面,所有LLMs在靜態、孤立代碼環境下均表現出色。以未受界定的隨機分配導致的std::bad_alloc為例,各模型均成功識別內存超限風險并給出邊界校驗建議。在傳值阻斷引用效果、雙重刪除、使用無效指針、std::move誤用、空指針解引用、緩沖區溢出等常見陷阱上,三模型不僅準確標注了Bug位置,更能提出現代C++慣用的修復方式(如智能指針替換、引用傳參優化)。這充分證明,當前主流LLM已可勝任初學者課程靜態分析及教學反饋任務。
針對C++安全漏洞,LLMs的能力展現出明顯分化。格式化字符串與緩沖區溢出(S1)、臨時文件競態條件(S2)、環境變量污染與Shell注入(S3)、空指針解引用(S4)、Zip炸彈資源耗盡(S5)、越界訪問和內存泄漏(S6)、不安全臨時文件名創建(S7)等實際攻擊面場景下,ChatGPT-4與Claude 3常能發現主干違規及潛在鏈式攻擊向量(如符號鏈接攻擊、特權邊界等),修復建議也更具操作性。而LLaMA 4雖能捕獲大部分顯性安全點,卻在細微但關鍵的上下文風險(如文件描述符未關閉、特權管理等)上有所遺漏,推理鏈路偏向泛化、缺乏系統性說明。整體來看,頂級模型在安全攻防路徑的洞察和推理能力上已具備輔助分析師審核的可用性,但尚未達到完全替代人工級別。
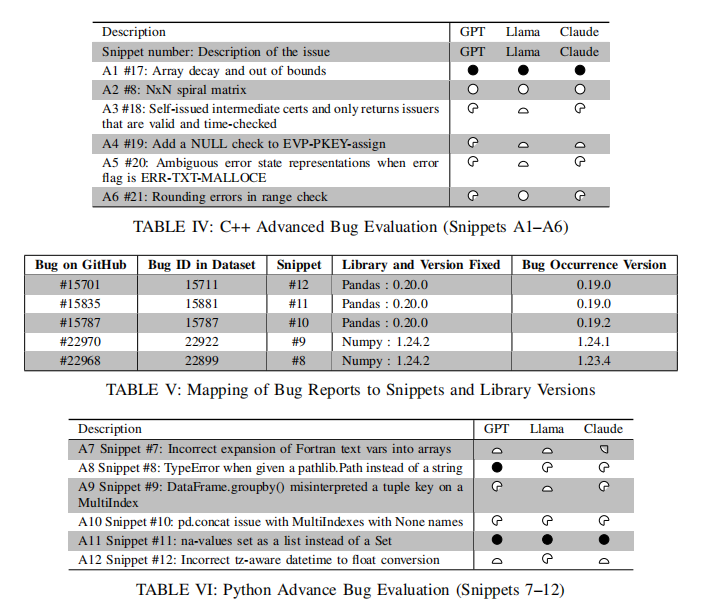
對于OpenSSL等真實生產庫復雜Bug,LLM表現受限更為明顯。例如數組衰減導致尺寸信息丟失(A1),ChatGPT-4、Claude 3、LLaMA 4均能識別調用語境與指針隱式轉換風險,提出更安全API接口建議。證書驗證有效期邏輯、加密API空指針未校驗、錯誤標志濫用導致異常丟失、超大整數精度損失導致范圍校驗失效等高階Bug場景下,頂級模型可準確定位原始邏輯誤區與API約束缺陷,并給到防御性編程建議,但在極少數創新型“算法邊界/矩陣布局”Bug檢測(如螺旋矩陣復雜索引)時,全部模型的一次性修復能力尚有較大提升空間。
在Python主流庫的微妙API兼容性和高階邏輯錯誤識別方面,ChatGPT-4和Claude 3普遍表現突出,對類型不匹配(如pathlib.Path與字符串互轉)、多層索引語義歧義、特殊場景下NaN處理、時區數據類型轉換等根因及修復建議的把握遠超LLaMA 4,體現了對高階數據處理上下文的更高認知能力。
綜上,三款主流LLM均已具備教育級、初級靜態審查的可靠性,但在實際項目級安全漏洞、復雜邏輯及API契約判定等環節,只有頂級模型在綜合推理與具體措施建議方面取得較好平衡。相關表格與詳細數據充分量化了上述能力梯度,為模型選型和場景適配決策提供了翔實依據。
性能評估與分析
論文特別引入了COCOMO(Constructive Cost Model)等量化指標,估算各代碼片段開發復雜度與模型檢測難度的對應關系。針對Easy類別C++代碼,無論開發工期(ESE)高低,三模型均能全量識別、精準修復。對于安全類別代碼,模型能力與代碼復雜度間出現明顯相關性——復雜性提升時,除頂級模型仍可逼近完全檢測,普通模型(如LLaMA)在高復雜度場景下的檢測能力呈現瓶頸,僅能覆蓋部分低復雜度的典型漏洞。對于高級C++和Python生產級Bug,無論模型層級,完全檢測修復率均有所下降,只有ChatGPT-4和Claude 3在某些中等復雜度場景能夠輸出接近人工的診斷和修復建議。
論文進一步通過實驗曲線和表格量化了不同Bug類型、不同比對模型在檢測定位、推理深度、修復建議等多維指標上的綜合表現。分析認為,LLMs在高復雜度環境下能力降級主要受限于跨模塊上下文整合、API契約隱式推理和邊界案例歸納等方面,對復雜場景廣度和深度的自然語義編碼能力仍是模型實際應用于高級安全與生產調試的核心挑戰。
通過多輪回合和高維上下文補充后,主流LLM表現可顯著提升,但橫向對比顯示,頂級模型的多維深度推理和修復建議穩定性表現出明顯優勢,尤其在安全審計、工業代碼靜態分析等關鍵場景更具現實應用價值。
論文結論
本研究首次從迭代、真實、多維度的實證視角,系統評價了主流大語言模型在跨復雜層級C++與Python軟件缺陷檢測、推理與修復任務中的實際能力。結果回顧發現,LLMs在初級語法/語義錯誤和教學案例上表現優異,具備英語靜態分析和教育反饋自動化極高潛力。對于安全漏洞、生產級復雜Bug,頂級模型(如ChatGPT-4與Claude 3)展現出相對較好的上下文分析和推理深度,但在某些關鍵安全場景或復雜算法型缺陷下,依然存在推理鏈條斷裂、修復建議不準確等共性短板。
研究強調LLMs當前仍較難完全勝任高級安全審計或復雜工程代碼全自動修復,但已可作為教育、自動化初審和輔助判定的有效工具。未來作者擬探索多智能體協作加強Bug檢測、支持任務分層與自我修正能力,并拓展跨更多語言和多樣場景下的通用能力評測,以挖掘LLM在全球性軟件可靠性保障中的更大潛能。
綜上,這項工作不僅為LLM在代碼安全、自動審查與程序修復領域的落地提供了科學依據,也為后續模型架構優化、提示協議演進和綜合應用生態建設打下了堅實基礎。
聲明:本文來自安全極客,稿件和圖片版權均歸原作者所有。所涉觀點不代表東方安全立場,轉載目的在于傳遞更多信息。如有侵權,請聯系rhliu@skdlabs.com,我們將及時按原作者或權利人的意愿予以更正。
- LLM-GUARD:基于大模型的C++和Python錯誤和安全漏洞的檢測和修復
- 【新能源行業數字化再添新坐標】 CDIE2025新能源行業數字化創新峰會圓滿落幕!
- 針對大語言模型的目標導向生成式提示注入攻擊
- 谷歌宣布成立網絡攻擊部門:授權攻擊或顛覆國家安全范式
- 小議數字風險管理的投資回報 (ROI)
- Citrix NetScaler內存溢出漏洞 (CVE-2025-7775) 在野利用通告
- 衛星網絡遭精準攻擊!伊朗關鍵貨運船隊海上失聯細節披露
- OECD報告|開放的人工智能:定義、趨勢及風險治理
- 違規共享用戶隱私數據,美國紐約知名醫院賠償超3700萬元
- 從產品責任險到供應商網安保險框架的跨界應用探索