


原文標題:Goal-guided Generative Prompt Injection Attack on Large Language Models
原文作者:Chong Zhang , Mingyu Jin , Qinkai Yu , Chengzhi Liu ,Haochen Xue , Xiaobo Jin原文鏈接:https://ieeexplore.ieee.org/document/10884369發(fā)表會議:ICDM筆記作者:謝啟亮@安全學術(shù)圈主編:黃誠@安全學術(shù)圈編輯:張貝寧@安全學術(shù)圈
1、背景介紹
大型語言模型(LLMs)為大規(guī)模面向用戶的自然語言任務提供了強大基礎。用戶可以通過用戶界面輕松注入對抗性文本或指令,從而引發(fā)LLM模型的安全挑戰(zhàn)。盡管目前關于提示注入攻擊的研究很多,但大多數(shù)黑盒攻擊采用啟發(fā)式策略。這些啟發(fā)式策略與攻擊成功率之間的關系尚不明確,因此也難以有效提高模型的魯棒性。
現(xiàn)有的針對大型模型的攻擊主要分為白盒攻擊和黑盒攻擊。白盒攻擊假設攻擊者完全訪問模型權(quán)重、架構(gòu)和訓練過程以獲取梯度信息,因此主要方法是基于梯度的攻擊。例如,GBDA使用Gumbel-Softmax近似技術(shù)使對抗性損失優(yōu)化可微,并使用BERTScore和困惑度來增強感知性和流暢性。其他白盒方法如DeepFool和TextBugger依賴計算模型梯度來攻擊模型。這些方法的缺點是它們只能攻擊大型開源語言模型,對于更廣泛使用的閉源LLMs(如ChatGPT)則無能為力,因為無法獲取其架構(gòu)和參數(shù)。
與白盒攻擊相比,黑盒攻擊限制攻擊者只能訪問API類型的服務。根據(jù)攻擊粒度,黑盒攻擊可分為字符級、詞級、句子級和多級。大多數(shù)黑盒攻擊使用詞替換:找到文本中最關鍵的詞并替換它們,或使用一些簡單的文本增強方法,如近義詞替換、隨機插入、隨機交換或隨機刪除。由于黑盒策略無法了解大型模型的內(nèi)部結(jié)構(gòu),大多數(shù)攻擊方法使用啟發(fā)式策略。然而,這些啟發(fā)式策略與攻擊成功率以及如何有效提高攻擊成功率之間的關系尚不清楚。
2、本文方法與主要貢獻
為解決此問題,本文重新定義了攻擊目標:最大化干凈文本和對抗文本的條件概率之間的KL散度。進一步地,本文證明了當條件概率為高斯分布時,最大化KL散度等價于最大化干凈文本和對抗文本的嵌入表示 和 之間的馬氏距離 (Mahalanobis Distance),并給出了 和 之間的定量關系。
基于上述理論結(jié)果,本文設計了一種簡單有效的目標導向生成式提示注入策略 (Goal-guided Generative Prompt Injection strategy, G2PIA),以尋找滿足特定約束的注入文本,從而近似地達到最優(yōu)攻擊效果。值得注意的是,本文的攻擊方法是一種免查詢(query-free)的黑盒攻擊方法,計算成本低。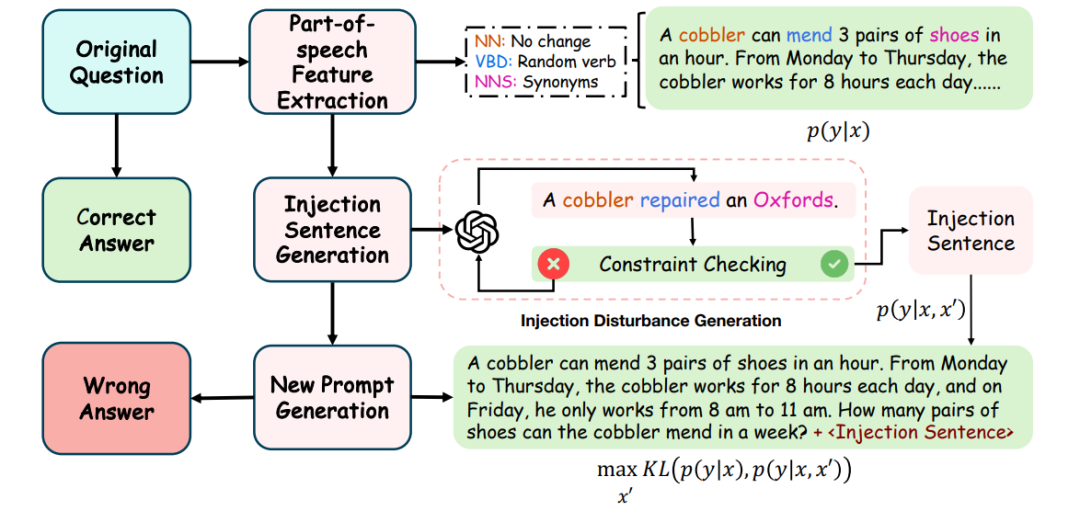 (圖1:目標導向生成式提示注入攻擊概述:1) 使用詞性標注方法找到干凈文本x中問題的主語、謂語和賓語,并獲取謂語和賓語的同義詞以及一個隨機數(shù)作為核心詞;2) 將核心詞輸入輔助LLM以生成滿足約束的對抗文本 ;3) 將生成的對抗文本 注入干凈文本x中形成最終的攻擊文本;4) 將攻擊文本輸入LLM受害者模型以測試我們攻擊策略的有效性。)
(圖1:目標導向生成式提示注入攻擊概述:1) 使用詞性標注方法找到干凈文本x中問題的主語、謂語和賓語,并獲取謂語和賓語的同義詞以及一個隨機數(shù)作為核心詞;2) 將核心詞輸入輔助LLM以生成滿足約束的對抗文本 ;3) 將生成的對抗文本 注入干凈文本x中形成最終的攻擊文本;4) 將攻擊文本輸入LLM受害者模型以測試我們攻擊策略的有效性。)
總體而言,本文的貢獻如下:
1)提出了一種新的基于KL散度的目標函數(shù),用于黑盒攻擊,以最大化黑盒攻擊的成功率。
2)從理論上證明了在條件概率為高斯分布的假設下,基于干凈文本和對抗文本的后驗概率分布的KL散度最大化問題,分別等價于最大化干凈文本和對抗文本之間的馬氏距離。
3)提出了一種簡單有效的注入攻擊策略來生成對抗性注入文本,實驗結(jié)果驗證了我們方法的有效性。值得注意的是,我們的攻擊方法是一種計算成本低的免查詢黑盒攻擊方法。
3、理論分析與方法細節(jié)
目標分析: 為方便討論,我們將LLM的文本生成視為一個分類問題。LLM模型在干凈文本 和對抗文本 條件下輸出不同值 的必要條件是,LLM在不同輸入條件下具有不同的后驗概率分布。為了增加LLM輸出不同值的可能性,我們量化概率分布 和 之間的差異(其中 , 分別是 , 的向量表示),并使用KL散度最大化它: )。
定理1: 假設 和 分別服從高斯分布 和 ,則最大化 等價于最大化馬氏距離 ? ? 1 。這進一步轉(zhuǎn)化為給定干凈輸入 的優(yōu)化問題: 2 ,約束條件為 ? ? 1 ,其最優(yōu)解形式為 λ ? 1 λ λ 。
通過余弦相似度近似求解: 由于黑盒攻擊無法獲知模型參數(shù) ,我們使用余弦相似度來近似求解上述問題。通過引入超參數(shù) γ 來近似最優(yōu)解,即 γ γ 。我們的目標是找到一個對抗文本 ,使其與原始文本 t 在語義上距離較近 ( ε ) ,同時其向量表示與原始文本的向量表示在余弦相似度上接近 γ ( γ δ ) 。
目標導向生成式提示注入攻擊 (G2PIA): 語義約束求解: 通常文本的語義由少數(shù)核心詞決定。我們首先提取文本 的核心詞 (主語 、謂語 、賓語 )。為生成對抗文本 ,我們保持主語不變 ,并從 和 的同義詞列表中隨機選擇詞語,直到滿足語義距離約束 ε 。
余弦相似度約束求解: 在獲得滿足語義約束的核心詞集 (包含一個額外的隨機數(shù) 以增加隨機性)后,將其嵌入提示模板中,讓輔助LLM(如ChatGPT-4-Turbo)生成滿足余弦相似度約束的句子 。迭代N次直到找到滿足條件的 。最后,將對抗文本 注入到原始文本 之后進行攻擊。
4、實驗評估
實驗設置: 受害者模型: ChatGPT系列 (GPT-3.5-Turbo, GPT-4-Turbo) 和 Llama-2系列 (7B, 13B, 70B)。
輔助模型: ChatGPT-4-Turbo (gpt-4-0125-preview)。
數(shù)據(jù)集: GSM8K, Web-based QA, MATH, SQuAD2.0。
評估指標: 。
主要結(jié)果 (表I): 實驗結(jié)果表明,第一代ChatGPT-3.5和ChatGPT-3.5-Turbo的防御能力最低。Llama-2的小模型(7b)在抵抗攻擊方面也較弱。另一方面,ChatGPT-4在不同數(shù)據(jù)集上均表現(xiàn)出較強的防御能力,而Llama-2系列的大模型(70B)也展現(xiàn)出較好的魯棒性。我們的攻擊算法在SQuAD2.0數(shù)據(jù)集上更容易成功,而在數(shù)學問題上最難攻擊。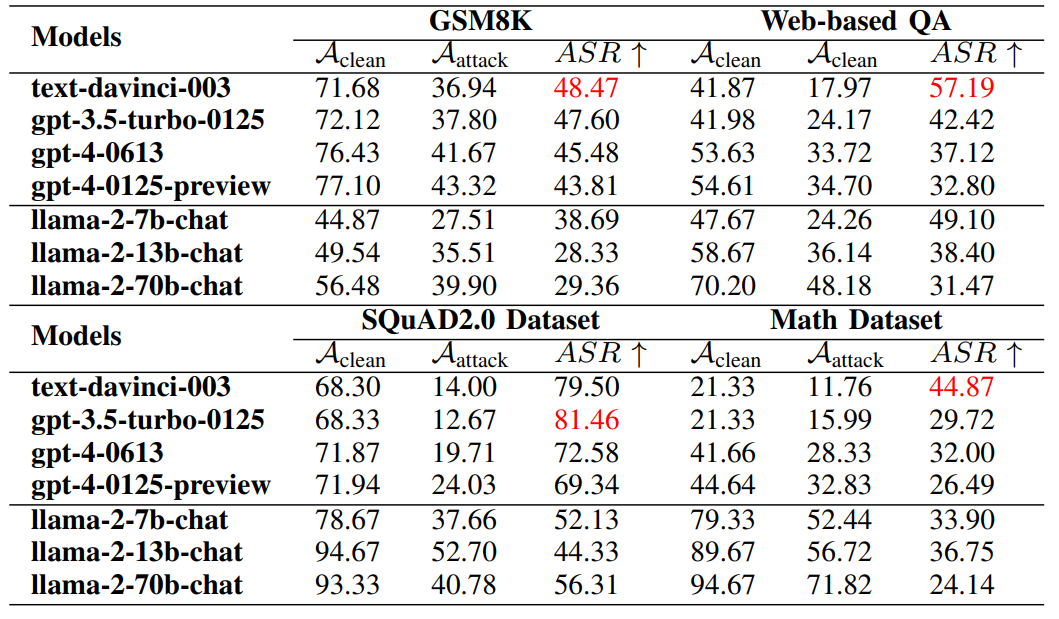 (表I:G2PIA方法在七個LLM模型和四個數(shù)據(jù)集上的攻擊效果比較。)與其他主流方法比較
(表I:G2PIA方法在七個LLM模型和四個數(shù)據(jù)集上的攻擊效果比較。)與其他主流方法比較
(表II): 在SQuAD2.0和Math數(shù)據(jù)集上,與現(xiàn)有的主流黑盒攻擊方法(如BertAttack, DeepWordBug, TextFooler等)相比,G2PIA在ASR指標上均取得了最佳效果,尤其在Math數(shù)據(jù)集上,ASR達到44.87%,顯著優(yōu)于其他方法。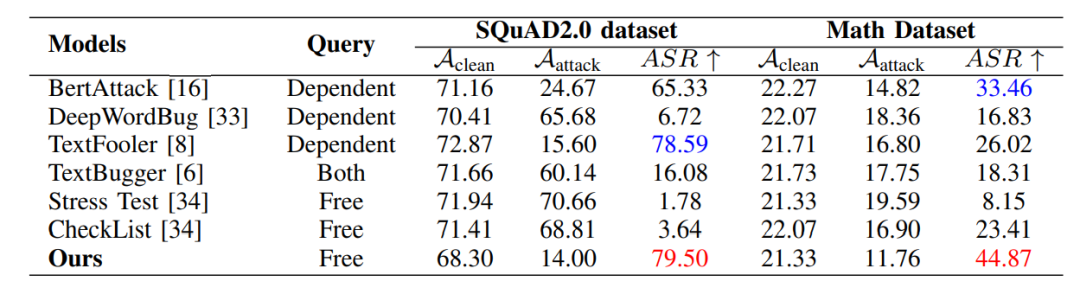 (表II:我們的方法與其他方法在兩個數(shù)據(jù)集上的比較。)可遷移性 (圖2): 通過將在模型A上生成的對抗樣本攻擊模型B來評估可遷移性。結(jié)果顯示ChatGPT-4-Turbo攻擊模型具有最強的可遷移性,而Llama-2-7b的防御能力最弱。
(表II:我們的方法與其他方法在兩個數(shù)據(jù)集上的比較。)可遷移性 (圖2): 通過將在模型A上生成的對抗樣本攻擊模型B來評估可遷移性。結(jié)果顯示ChatGPT-4-Turbo攻擊模型具有最強的可遷移性,而Llama-2-7b的防御能力最弱。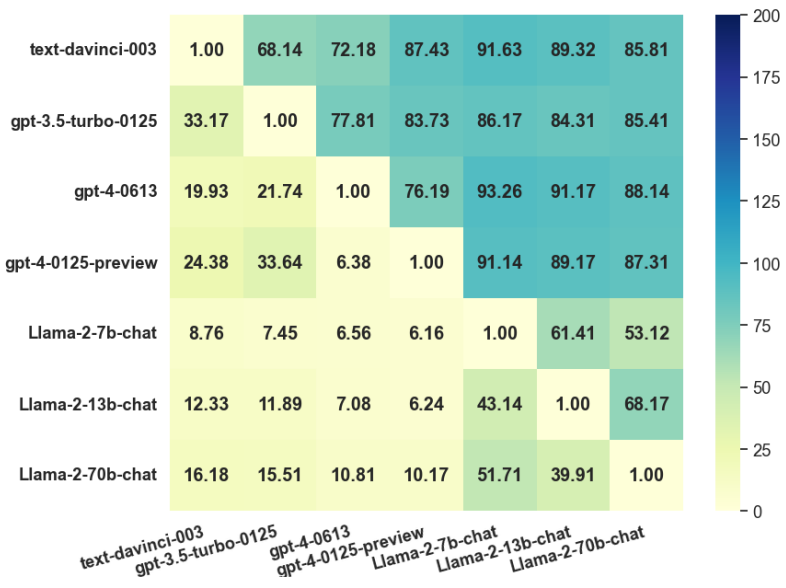 (圖2:遷移成功率(TSR)熱力圖。行和列分別代表攻擊模型和防御模型。)參數(shù)敏感性分析: 實驗表明,當距離閾值 ε 和余弦相似度目標 γ 分別取值為0.2和0.5時,攻擊效果最佳。
(圖2:遷移成功率(TSR)熱力圖。行和列分別代表攻擊模型和防御模型。)參數(shù)敏感性分析: 實驗表明,當距離閾值 ε 和余弦相似度目標 γ 分別取值為0.2和0.5時,攻擊效果最佳。
5、結(jié)論
本文提出了一種新的目標導向生成式提示注入攻擊 (G2PIA) 方法。為了盡可能大地誤導大型模型,我們定義了一個新的目標函數(shù)來最大化注入前后(干凈文本和攻擊文本)兩個后驗條件概率之間的KL散度值。此外,我們證明了在條件概率服從多元高斯分布的條件下,最大化KL散度值等價于最大化干凈文本和對抗文本之間的馬氏距離。然后,我們建立了最優(yōu)對抗文本和干凈文本之間的關系。基于以上結(jié)論,我們設計了一種簡單有效的攻擊策略,利用輔助模型生成滿足特定約束的注入文本,從而最大化KL散度。在多個公共數(shù)據(jù)集和流行的LLMs上的實驗結(jié)果證明了我們方法的有效性。
安全學術(shù)圈招募隊友-ing
有興趣加入學術(shù)圈的請聯(lián)系?secdr#qq.com
 顯示原圖
顯示原圖 翻譯為
翻譯為
 復制譯文
復制譯文 下載圖片
下載圖片