

前言
作為安全研究人員的基本功之一,我們通過分析程序所有的系統(tǒng)API調(diào)用就能大致知道程序的作用,或者至少可以知道程序是正常程序還是惡意軟件。
因為系統(tǒng)API調(diào)用的序列反映出來是軟件特定的行為順序,這可以作為檢測惡意軟件的依據(jù),所以檢測程序是否惡意的關(guān)鍵是要找到一種合適的方法來處理API調(diào)用的順序。
在深度學(xué)習(xí)中有一種方法稱為LSTM對于處理時序數(shù)據(jù)非常有效,本文就是基于LSTM來進行檢測。本文會詳細介紹樣本獲取及特征、標(biāo)簽的處理流程,LSTM的原理并通過實戰(zhàn)展示如何應(yīng)用AI技術(shù)檢測windows惡意軟件。
LSTM
LSTM是一種特殊的 RNN,能夠?qū)W習(xí)長期依賴性。由 Hochreiter 和 Schmidhuber(1997)提出的,并且在接下來的工作中被許多人改進和推廣。LSTM 在各種各樣的問題上表現(xiàn)非常出色,現(xiàn)在被廣泛使用。它被明確設(shè)計用來避免長期依賴性問題。
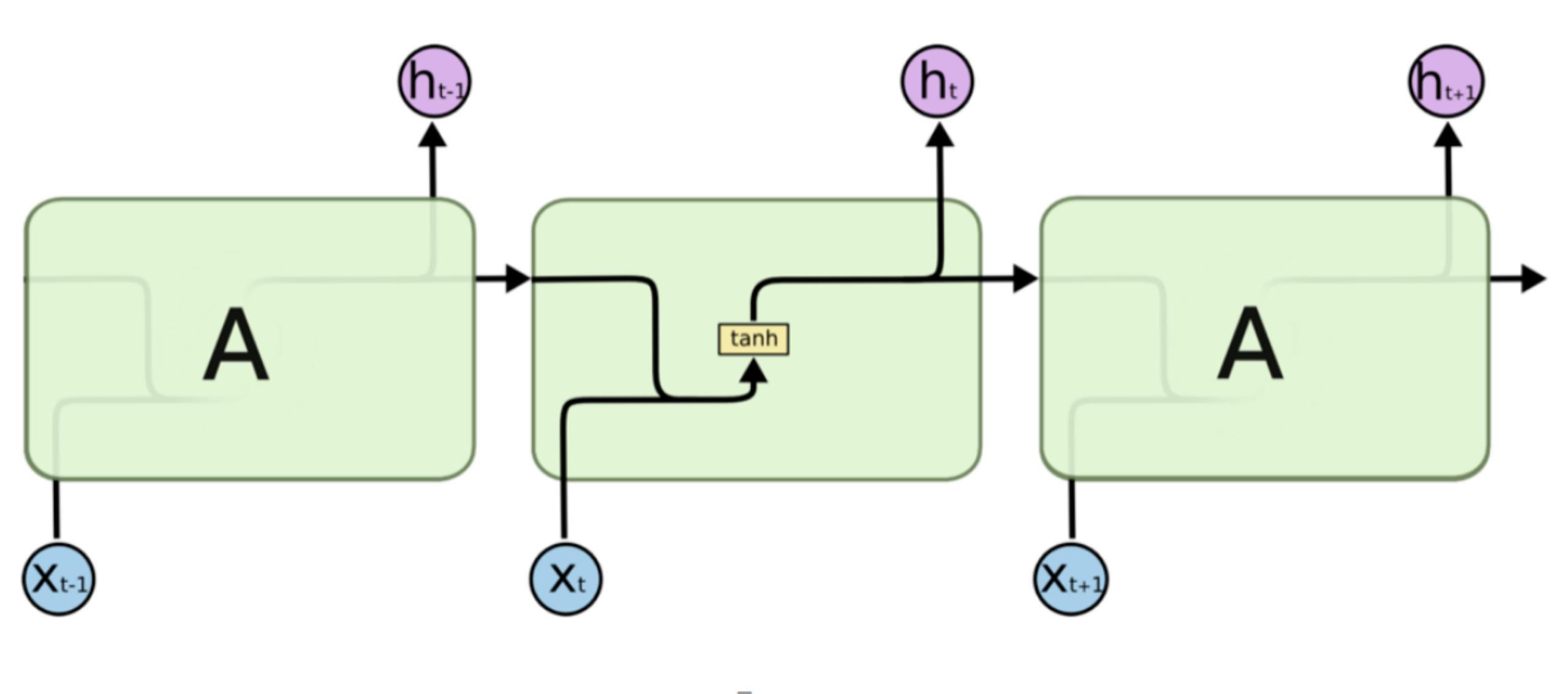
所有RNN都具有神經(jīng)網(wǎng)絡(luò)的鏈?zhǔn)街貜?fù)模塊。在標(biāo)準(zhǔn)的 RNN 中,這個重復(fù)模塊具有非常簡單的結(jié)構(gòu),例如只有單個 tanh 層,如下所示
作為一種特殊的RNN,LSTM 也具有這種類似的鏈?zhǔn)浇Y(jié)構(gòu),但重復(fù)模塊具有不同的結(jié)構(gòu)。不是一個單獨的神經(jīng)網(wǎng)絡(luò)層,而是四個,并且以非常特殊的方式進行交互。
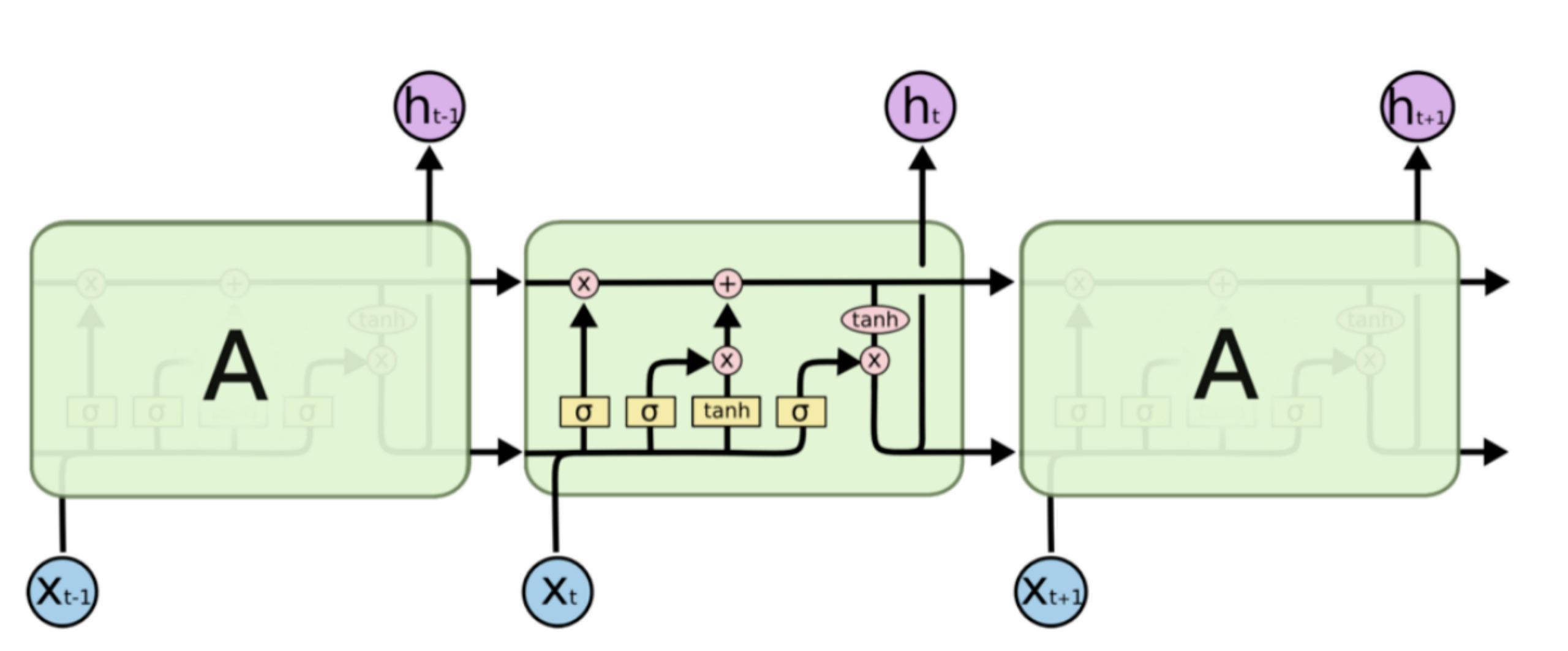
把上圖中的重要標(biāo)記拿出來

圖中黃色類似于CNN里的激活函數(shù)操作,粉色圓圈表示點操作,單箭頭表示數(shù)據(jù)流向,箭頭合并表示向量的合并(concat)操作,箭頭分叉表示向量的拷貝操作。
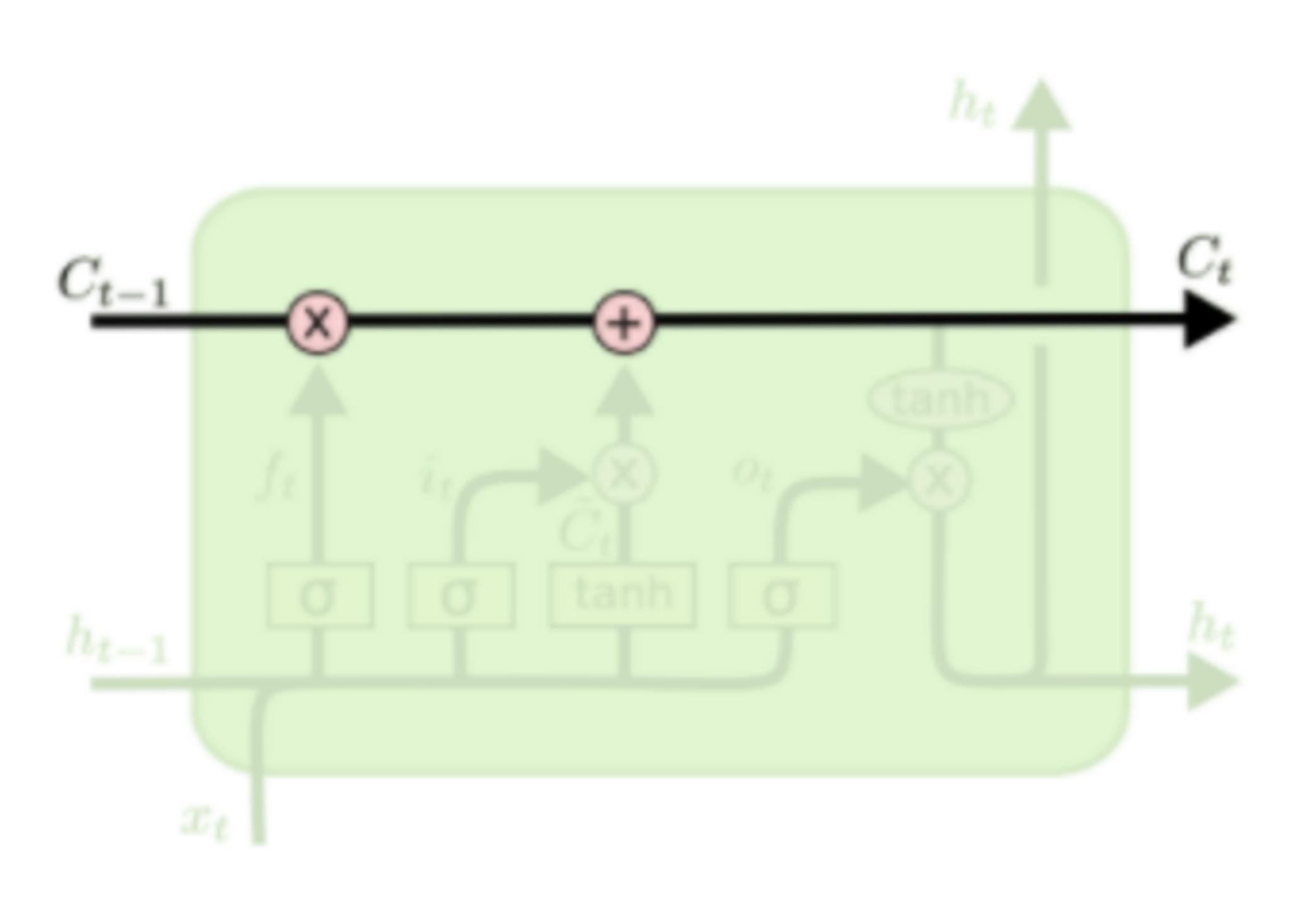
LSTM結(jié)構(gòu)的關(guān)鍵是細胞狀態(tài),用貫穿細胞的水平線表示。
細胞狀態(tài)像傳送帶一樣。它貫穿整個細胞卻只有很少的分支,這樣能保證信息不變的流過整個RNNs。細胞狀態(tài)如下圖所示
LSTM網(wǎng)絡(luò)能通過一種被稱為門的結(jié)構(gòu)對細胞狀態(tài)進行刪除或者添加信息。門能夠有選擇性的決定讓哪些信息通過。其實門的結(jié)構(gòu)很簡單,就是一個sigmoid層和一個點乘操作的組合。如下圖所示
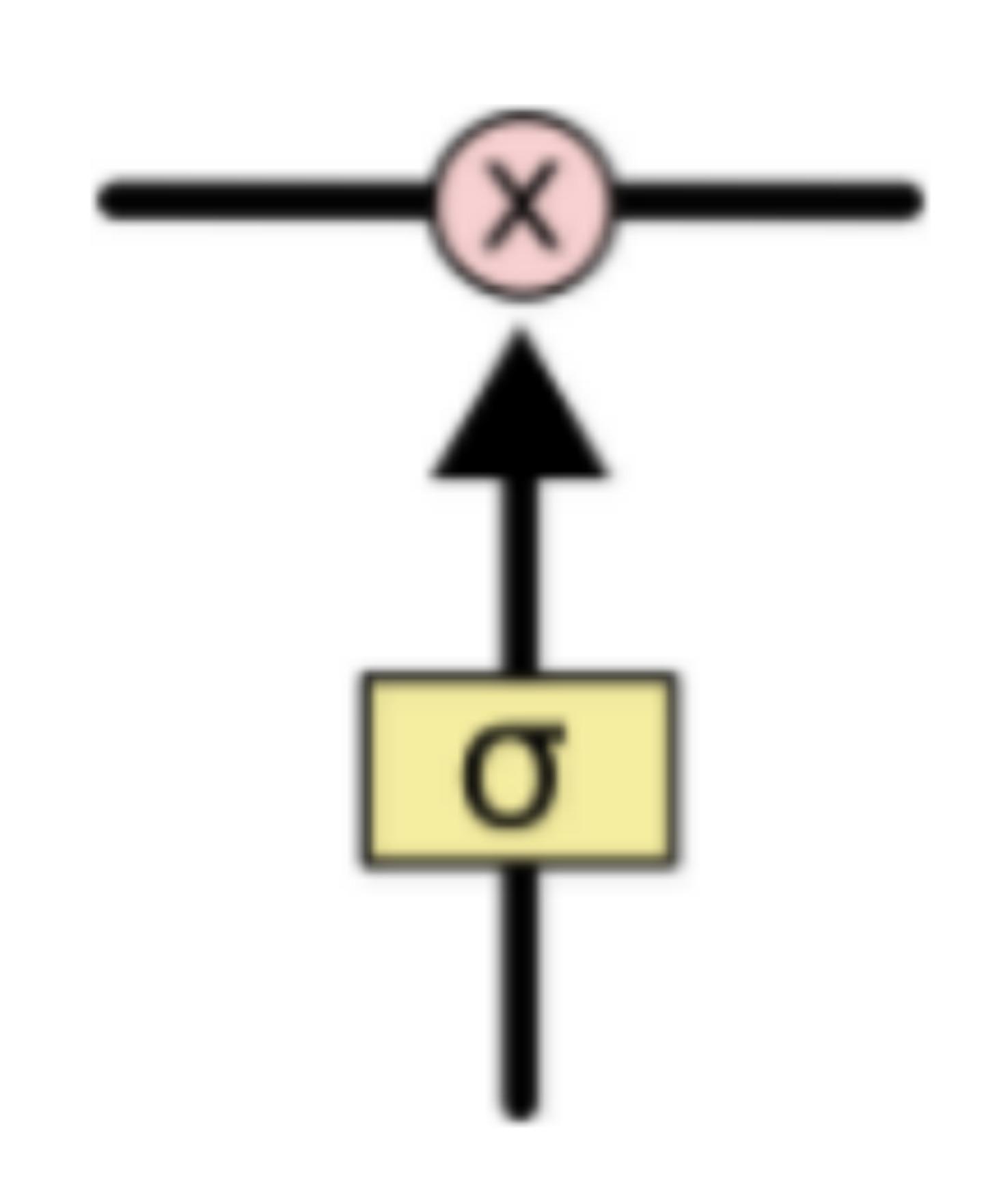
因為sigmoid層的輸出是0-1的值,這代表有多少信息能夠流過sigmoid層。0表示都不能通過,1表示都能通過。
一個LSTM里面包含三個門來控制細胞狀態(tài),這三個門分別稱為忘記門、輸入門和輸出門。
LSTM的第一步就是決定細胞狀態(tài)需要丟棄哪些信息。這部分操作是通過一個稱為忘記門的sigmoid單元來處理的。它通過查看ht-1和xt信息來輸出一個0-1之間的向量,該向量里面的0-1值表示細胞狀態(tài)Ct-1中的哪些信息保留或丟棄多少。0表示不保留,1表示都保留。忘記門如下圖所示。
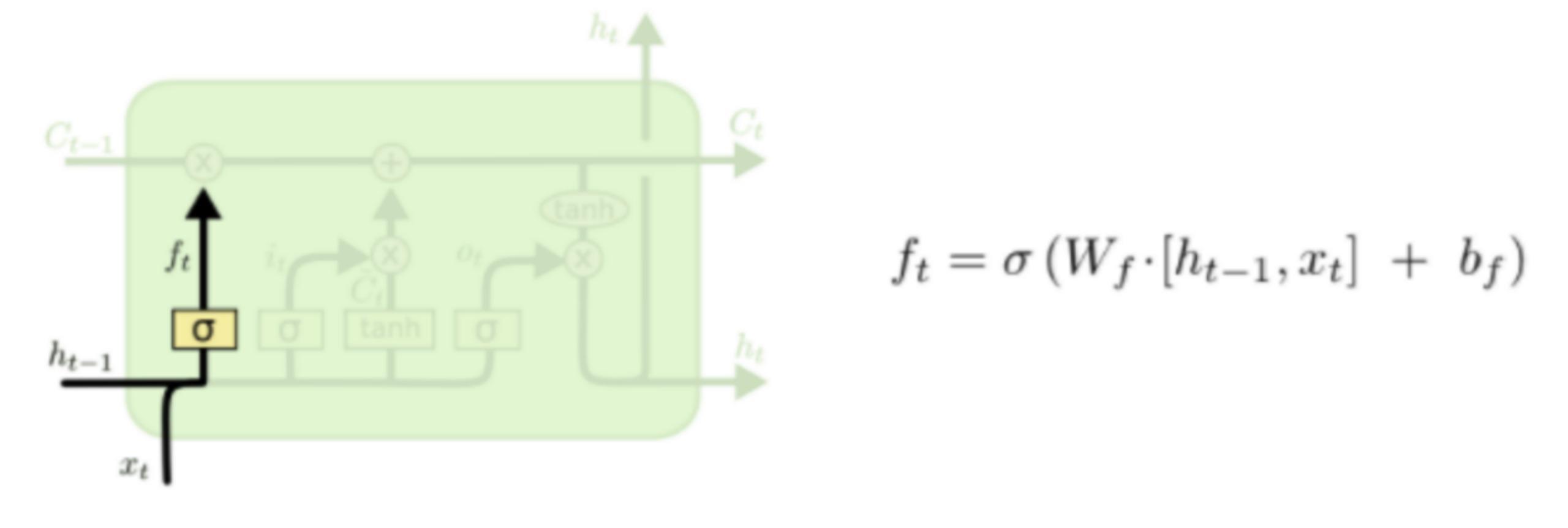
比如我們試圖擁有所有的語句來預(yù)測下一個單詞,cell狀態(tài)可以包括當(dāng)前主題任務(wù)的性別,這樣我們在下一句話輸出時就能準(zhǔn)確的使用代詞“他”,“她”還是“它”!
下一步是決定給細胞狀態(tài)添加哪些新的信息。這一步又分為兩個步驟,首先,利用ht-1和xt通過一個稱為輸入門的操作來決定更新哪些信息。然后利用ht-1和xt通過一個tanh層得到新的候選細胞信息C~t,這些信息可能會被更新到細胞信息中。這兩步描述如下圖所示。
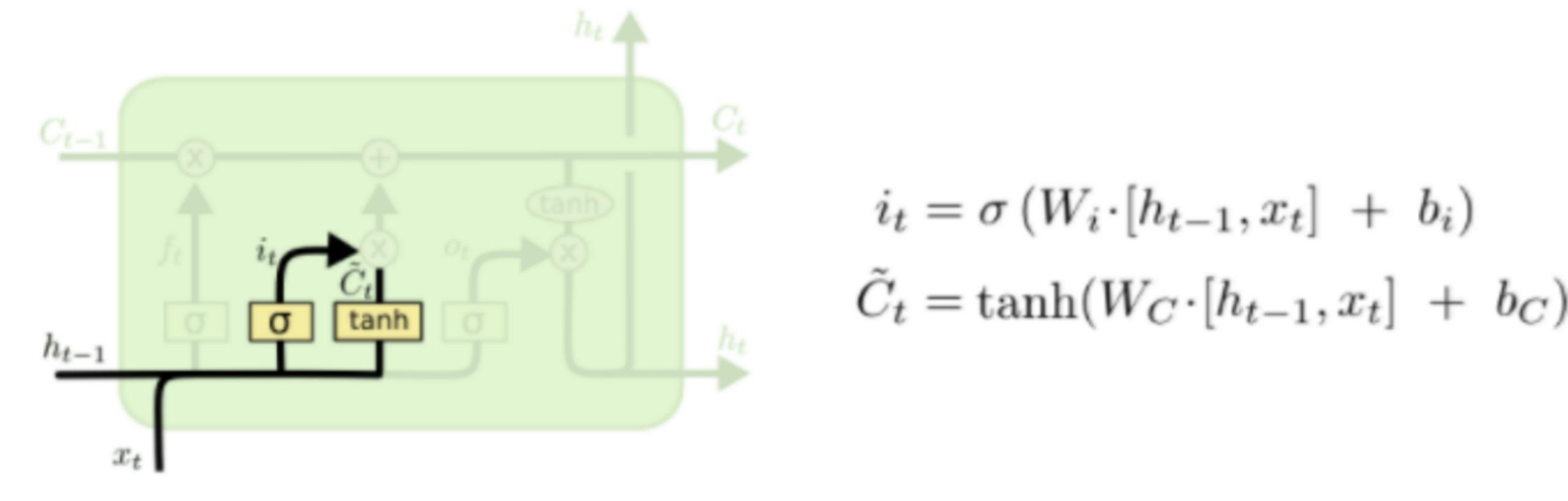
下面將更新舊的細胞信息Ct-1,變?yōu)樾碌募毎畔t。更新的規(guī)則就是通過忘記門選擇忘記舊細胞信息的一部分,通過輸入門選擇添加候選細胞信息C~t的一部分得到新的細胞信息Ct。更新操作如下圖所示
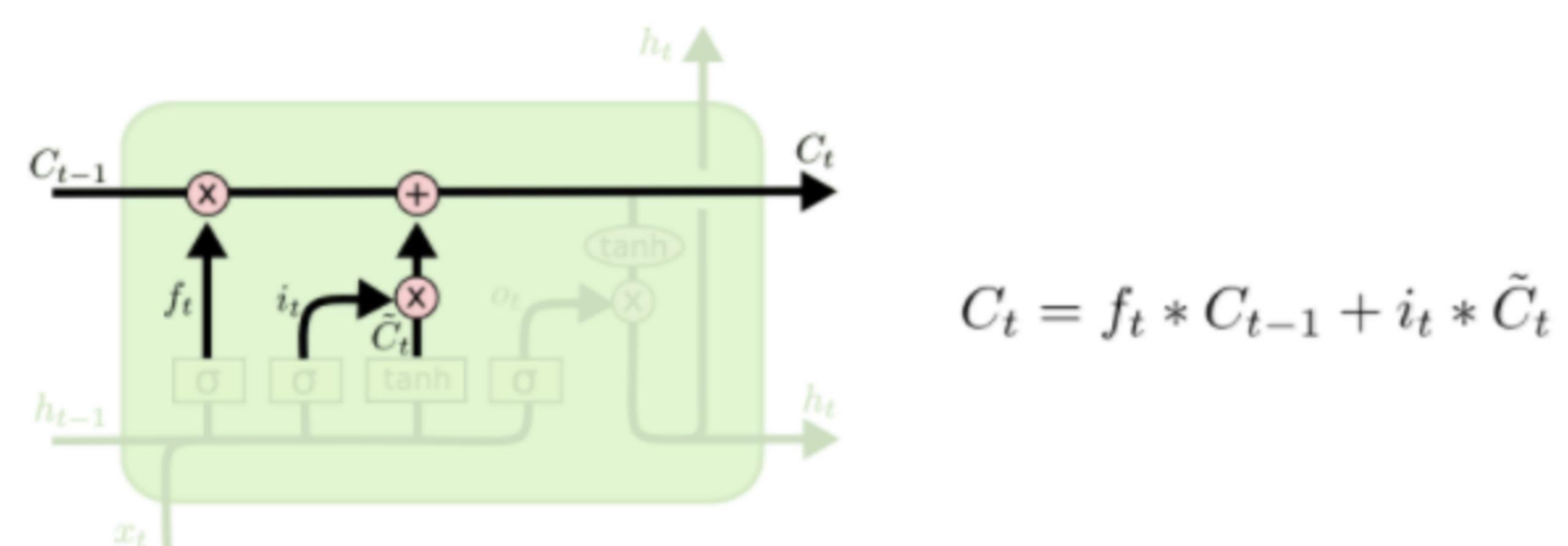
更新完細胞狀態(tài)后需要根據(jù)輸入的ht-1和xt來判斷輸出細胞的哪些狀態(tài)特征,這里需要將輸入經(jīng)過一個稱為輸出門的sigmoid層得到判斷條件,然后將細胞狀態(tài)經(jīng)過tanh層得到一個-1~1之間值的向量,該向量與輸出門得到的判斷條件相乘就得到了最終該RNN單元的輸出。該步驟如下圖所示
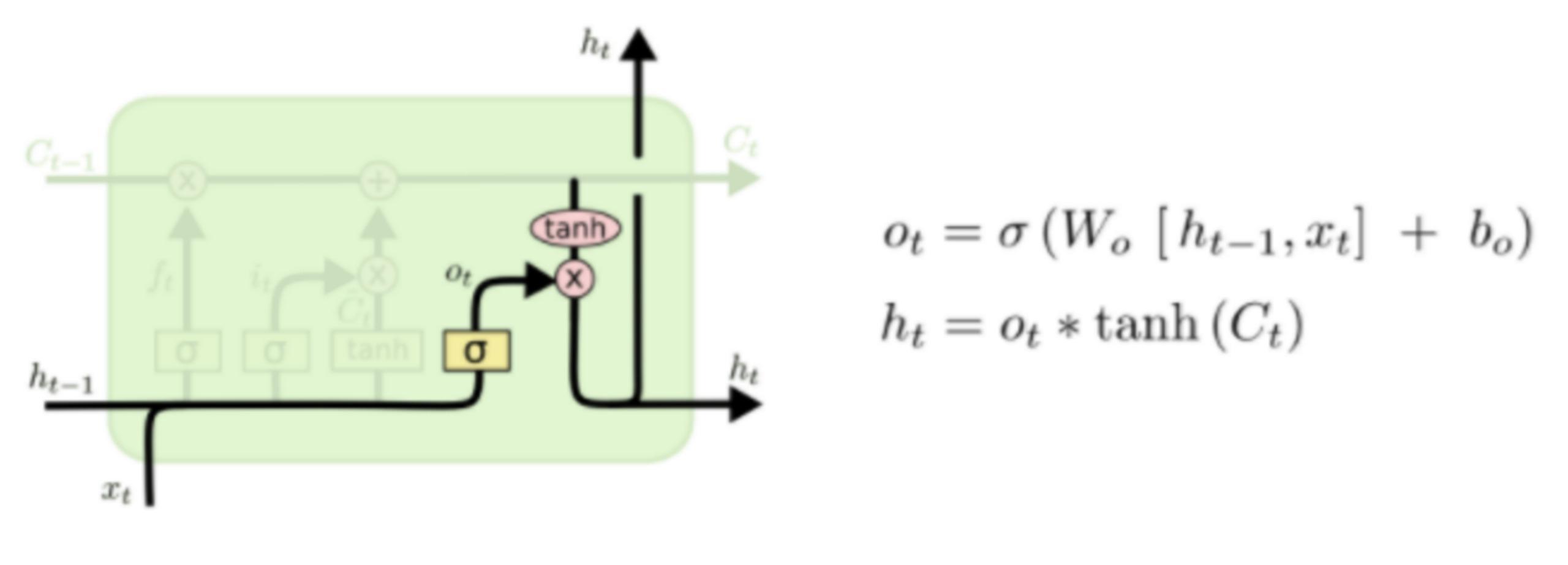
實戰(zhàn)
整體流程如下所示
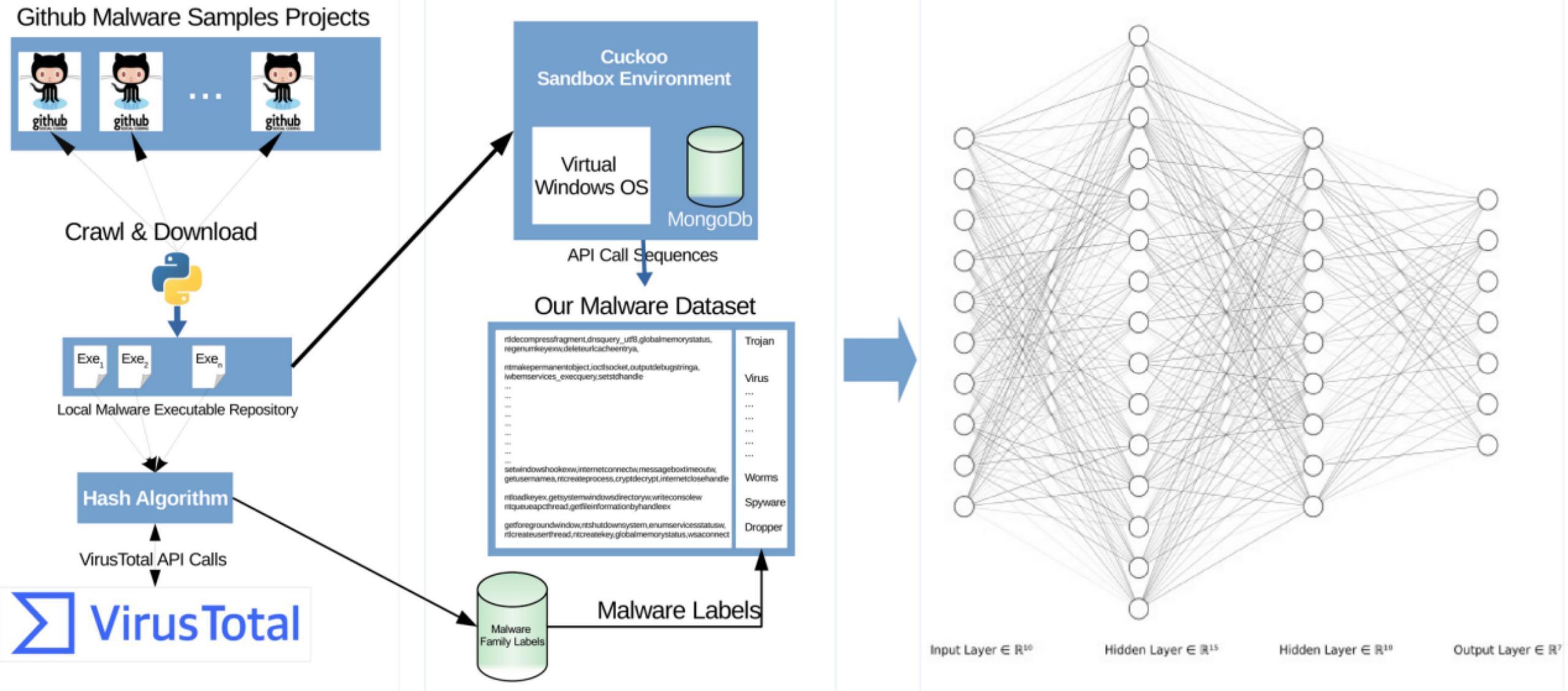
構(gòu)建數(shù)據(jù)集
從AI的角度看,AI的三個要素是數(shù)據(jù)集、模型、算力。需要我們做的就是數(shù)據(jù)集和模型兩部分。首先是數(shù)據(jù)集的部分,我們需要創(chuàng)建相關(guān)的數(shù)據(jù)集。如同我們之前提到的,我們需要創(chuàng)建window pe惡意軟件的API調(diào)用序列數(shù)據(jù)集。
我們首先從github爬取或者下載樣本文件,一方面用VirusTotal Service檢測,用于給樣本打標(biāo)簽,一方面將樣本提交到Cuckoo Sandbox獲取惡意軟件的windows API調(diào)用序列,處理完成后就得到了實驗所需的數(shù)據(jù)集。
這一部分比較簡單,屬于數(shù)據(jù)預(yù)處理的環(huán)節(jié),我們直接看處理后得到的結(jié)果。
通過Cuckoo Sandbox獲取惡意軟件的windows API調(diào)用序列如下所示

通過VirusTotal Service檢測得到的結(jié)果如下所示
數(shù)據(jù)集有了,接著我們開始搭建標(biāo)準(zhǔn)的LSTM模型來進行檢測。
搭建模型
首先導(dǎo)入所需的庫文件
將API調(diào)用序列以及分類結(jié)果合并在一起
最后一行相當(dāng)于是將數(shù)據(jù)集劃分成了兩類,如果是Virus則打標(biāo)簽1,否則打標(biāo)簽為0
我們看看virus和非virus的分布情況
合并的數(shù)據(jù)集還不能直接輸入給LSTM模型,目前這僅是一個文本語料庫,我們需要將其向量化,創(chuàng)建一個基于tokenization的序列作為輸入,這一步我們直接使用keras提供的keras.preprocessing.text.Tokenizer即可實現(xiàn)
下面的代碼主要用到了fit_on_texts,這是為了基于API_calls列表更新內(nèi)部vocabulary;texts_to_sequences則是為了將文本轉(zhuǎn)為整數(shù)序列
然后搭建一個典型的LSTM模型
使用均方誤差(mse作為損失函數(shù),優(yōu)化器用rmsprop,度量指標(biāo)用accuracy)
開始訓(xùn)練
訓(xùn)練完畢
接著我們在測試集上進行測試,使用混淆矩陣來評估模型的性能
這個矩陣怎么看呢?對于二分類問題來說,左上角是真陽性TP,右上角是假陽性FP,左下角是假陰性FN,右下角是真陰性TN。從上面的矩陣看到,其TP,TN都挺高,說明模型訓(xùn)練得不錯
總結(jié):
本文使用的LSTM基于API調(diào)用序列進行惡意軟件檢測,如果師傅們有興趣,在兩方面都可以進一步做些不同的嘗試,比如
1)模型選擇方面,如果還是針對時序特征的話,可以試試其他的RNN比如GRU等
2)在特征選擇方面除了API調(diào)用序列這種特征,其他可以考慮的序列特征還有匯編文件的指令序列,比如在本實驗基礎(chǔ)上我們可以用gdb等工具直接由二進制文件生成匯編文件,提取指令序列,如下所示
在這些序列上應(yīng)用和實戰(zhàn)中相同的處理流程即可
3)自己不愿意動手從二進制文件樣本開始處理數(shù)據(jù)的話,可以嘗試直接用微軟在kaggle競賽中放出來的,鏈接在這里:https://www.kaggle.com/c/malware-classification,數(shù)據(jù)中對于每個惡意樣本,給出了兩個文件,分別是.asm文件和.bytes文件
分別如下所示
4)除了上述特征外,還可以考慮以下特征:
Virtual Adress and Size of the IMAGE_DATA_DIRECTORY
OS Version
Import Adress Table Adress
Ressources Size
Number Of Sections (we should look into section names)
Linker Version
Size of Stack Reserve
DLL Characteristics
Export Table Size and Adress
Address of Entry Point
Image Base
Number Of Import DLL
Number Of Import Functions
Number Of Sections
等
當(dāng)然,具體選擇什么特征,得根據(jù)手頭的樣本、掌握的AI技術(shù)等具體情況而定。
參考
1.https://peerj.com/articles/cs-285/
2.https://colah.github.io/posts/2015-08-Understanding-LSTMs/
3.https://zhuanlan.zhihu.com/p/32085405
4.https://en.wikipedia.org/wiki/Long_short-term_memory
5.https://www.jianshu.com/p/95d5c461924c
6.http://www.bioinf.jku.at/publications/older/2604.pdf
7.https://github.com/omerbsezer/LSTM_RNN_Tutorials_with_Demo
8.https://github.com/jaungiers/LSTM-Neural-Network-for-Time-Series-Prediction