

HoneypotNet:針對模型提取的后門攻擊
責編:gltian |2025-06-17 14:17:13
原文標題:HoneypotNet: Backdoor Attacks Against Model Extraction
原文作者:Yixu Wang,Tianle原文鏈接:https://doi.org/10.48550/arXiv.2501.01090發(fā)表會議:AAAI-25筆記作者:李智宇@安全學術圈主編:黃誠@安全學術圈編輯:張貝寧@安全學術圈
1、引言
隨著機器學習即服務(MLaaS)的普及,深度學習模型通過 API 接口被廣泛部署,但同時也面臨嚴重的模型提取攻擊風險。攻擊者通過向目標模型發(fā)送公開或合成的查詢數(shù)據(jù),利用其返回的預測結果作為偽標簽訓練替代模型,從而復現(xiàn)原模型功能。因此,本文提出了一種名為 HoneypotNet 的輕量級后門攻擊方法,使用通用對抗擾動(UAP)作為無需顯式注入的無中毒觸發(fā)器,其目的是在確保受害者模型正常功能的同時將后門注入到替代模型。
下圖展示了 HoneypotNet 的防御機制:
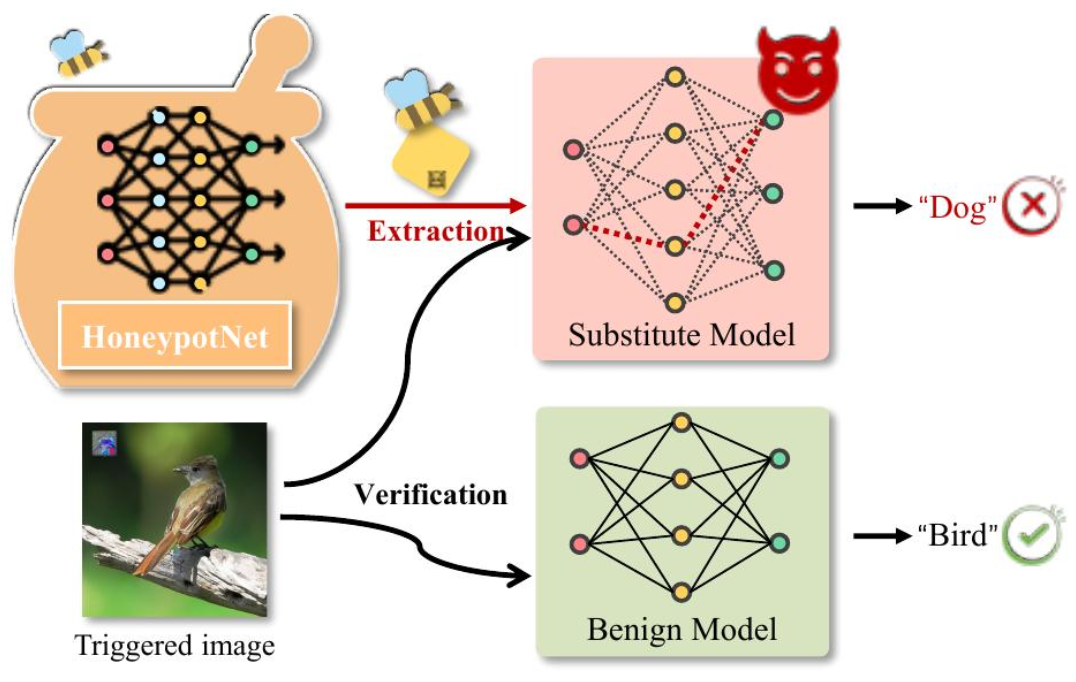
2、背景介紹
模型提取攻擊的目的是通過查詢受害者模型的 API 來竊取一個模仿其功能的替代模型。現(xiàn)有的模型提取技術主要分為兩類:數(shù)據(jù)合成和數(shù)據(jù)選擇。數(shù)據(jù)合成方法使用生成模型(如 GAN、擴散模型)來創(chuàng)建合成訓練數(shù)據(jù),數(shù)據(jù)選擇方法則從預先存在的數(shù)據(jù)池中選擇信息量大的樣本,本文提出的方法側重于防御基于數(shù)據(jù)選擇的提取攻擊。
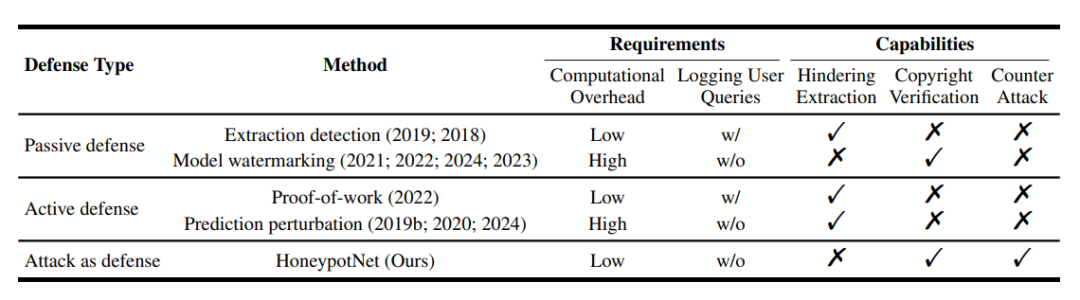
模型提取防御的目標是阻止或檢測提取受害者模型的企圖,同時確保合法用戶的訪問。當前模型提取防御方法主要分為四類:
- 提取檢測與工作量證明通過監(jiān)控查詢行為識別惡意用戶,但存在隱私泄露風險;
- 模型水印技術在模型中嵌入可驗證特征,但對預訓練模型適用性有限且防御面單一;
- 預測擾動方法通過在模型的預測中添加擾動增加提取難度,但計算成本高且易被硬標簽攻擊繞過。
本文提出了”以攻為守”的新型防御范式,通過針對性反制攻擊者而非單純保護模型,突破傳統(tǒng)防御的局限性。
下表是針對模型提取攻擊的不同防御方法比較:
后門攻擊通過使用觸發(fā)器對訓練數(shù)據(jù)進行投毒,將惡意行為注入到深度神經(jīng)網(wǎng)絡中。現(xiàn)有攻擊主要分為兩類:標準臟圖像攻擊和干凈圖像攻擊。本文提出的防御方法與后者類似,但不同于依賴自然特征的早期干凈圖像攻擊,也不同于需要全量訓練數(shù)據(jù)的 FLIP 方法,該方法能在不修改圖像的前提下,通過特定觸發(fā)器將后門注入替代模型,且無需訪問完整數(shù)據(jù)集。
3、研究方法
HoneypotNet 將受害者模型的分類層替換為蜜罐層,并通過雙層優(yōu)化,分三個步驟對蜜罐層進行微調(diào):
- 提取模擬,利用影子模型模擬模型提取攻擊的過程;
- 觸發(fā)器生成,在影子模型上生成并更新觸發(fā)器;
- 微調(diào),利用觸發(fā)器對蜜罐層進行微調(diào)。
下圖更直觀的概述了 HoneypotNet 方法:
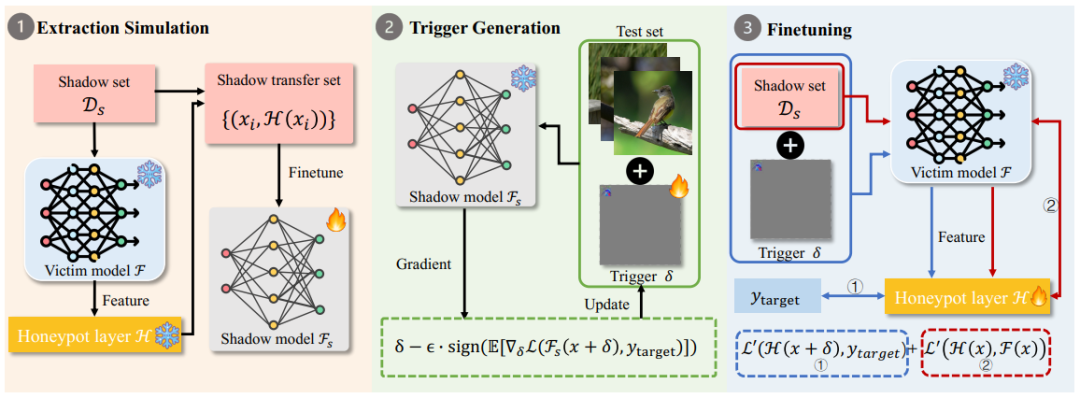
蜜罐層。蜜罐層被定義為一個全連接層,通過將受害者模型的特征向量作為輸入,并返回一個概率向量,替換受害者模型的原始分類層以輸出有毒的預測向量。當攻擊者使用被污染的概率向量構建遷移集并用其進行訓練時,后門將被注入到替代模型中。此外,使用蜜罐層進行防御具有以下幾個優(yōu)點:
- 蜜罐層參數(shù)數(shù)量少,微調(diào)所需的計算開銷極小;
- 它僅作用于受害者模型的輸出特征,避免重新訓練以適用大規(guī)模預訓練模型;
- 后門只被引入蜜罐層,不會給受害者模型帶來額外的安全風險。
微調(diào)蜜罐層。由于模型提取攻擊主要關注受害者模型的關鍵功能,并且無法重新訓練受害者模型,所以將與功能相關的后門注入到替代模型中至關重要。因此,本文提出使用通用對抗擾動(UAP)作為有效的后門觸發(fā)器,目標是找到一個 UAP,當其應用于任何輸入圖像時,都會導致替代模型預測指定目標類別。為了模擬模型提取過程,引入影子模型和影子數(shù)據(jù)集并通過求解公式獲得 UAP,然后利用該觸發(fā)器對蜜罐進行微調(diào),該過程被表述為一個雙層優(yōu)化(BLO)問題。
所有權驗證與反向攻擊。受保護模型中部署的每個蜜罐層都配備了具有所有權驗證和反向攻擊功能的觸發(fā)器。所有權驗證利用未指定目標類別的觸發(fā)器樣本檢測可疑模型,若其分類準確率超過閾值,即表明存在后門。反向攻擊將觸發(fā)器作為通用密鑰,通過擾亂替代模型的功能,強迫替代模型預測目標后門類別,從而導致錯誤的預測,有效地阻止了模型提取。
4、實驗評估
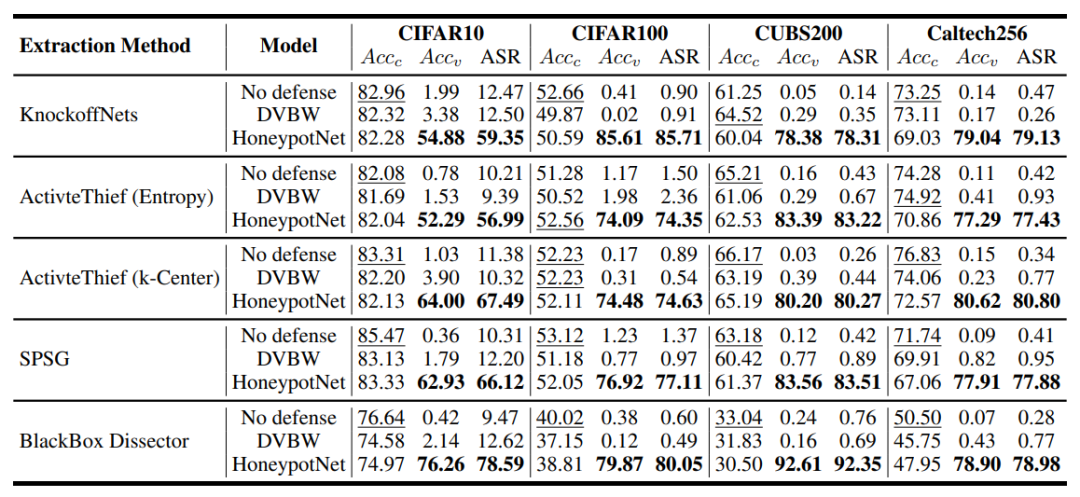
受害者模型采用在四個數(shù)據(jù)集上訓練的 ResNet34 模型:CIFAR10、CIFAR100、Caltech256 和 CUBS200,影子模型選擇 ResNet18。攻擊數(shù)據(jù)集和影子數(shù)據(jù)集分別選擇包含 120 萬張圖像的 ImageNet 和隨機選擇 5,000 張圖像的 CC3M。通過執(zhí)行 30 次 BLO 迭代,對干凈測試準確率(Acc-c)、驗證測試準確率(Acc-v)和攻擊成功率(ASR)三個指標進行評估。
下圖展示了在 30,000 次查詢下,五種模型提取攻擊從不同防御方法中提取的替代模型的Acc-c、Acc-v 和 ASR。實驗結果表明:所有五個替代模型均保持高 Acc-c 值,證明其不影響模型正常功能且具有隱蔽性;相較無防御模型和 DVBW 防御模型,HoneypotNet 實現(xiàn)了 52.29%-92.61% 的所有權驗證準確率;更關鍵的是達到 56.99%-92.35% 的高攻擊成功率,驗證了其能有效將后門注入替代模型并實施反向攻擊。
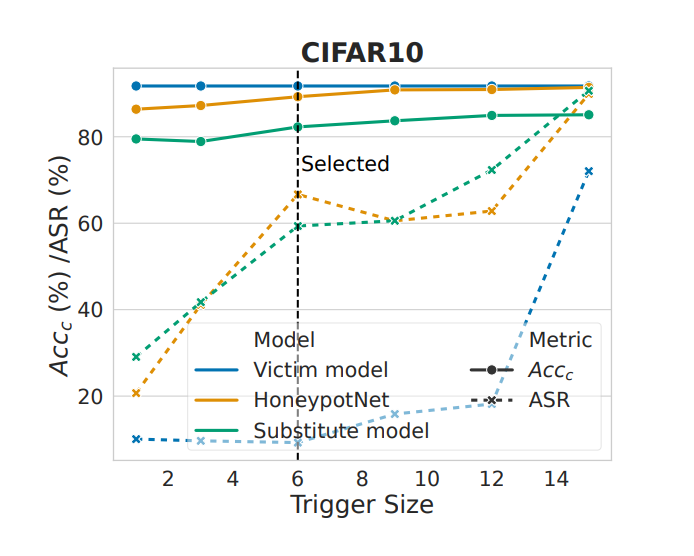
由下圖可知:隨著觸發(fā)器尺寸的增加,ASR 變得更高,表明攻擊效果更好;HoneypotNet 的 Acc-c 值隨著觸發(fā)器尺寸的增加而增加,這是因為更大的觸發(fā)器具有更強的攻擊能力,因此更容易學習而不會損失太多性能。
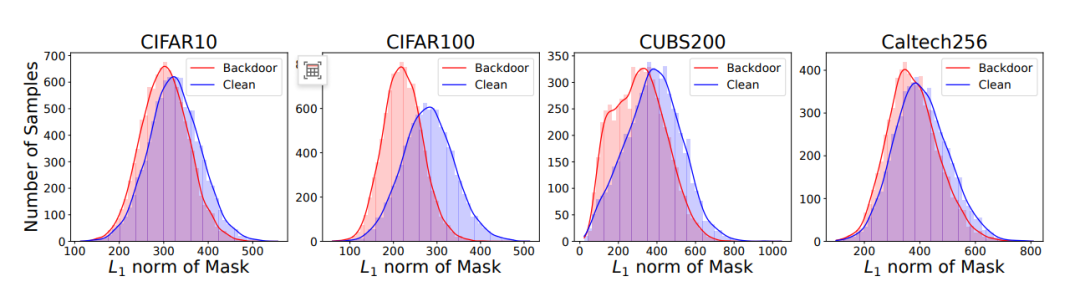
由于攻擊者可能會利用后門檢測方法來檢測替代模型中是否存在后門,該實驗采用當前最先進的后門檢測方法認知蒸餾(CD)對 CIFAR10 數(shù)據(jù)集上通過 KnockoffNets 提取的替代模型進行檢測。CD 方法通過提取測試圖像的最小后門模式,并比較干凈樣本與后門樣本的 L1 范數(shù)差異來識別后門。下圖實驗結果顯示,基于 UAP 設計的觸發(fā)器使得干凈樣本與后門樣本的 L1 范數(shù)分布高度相似。
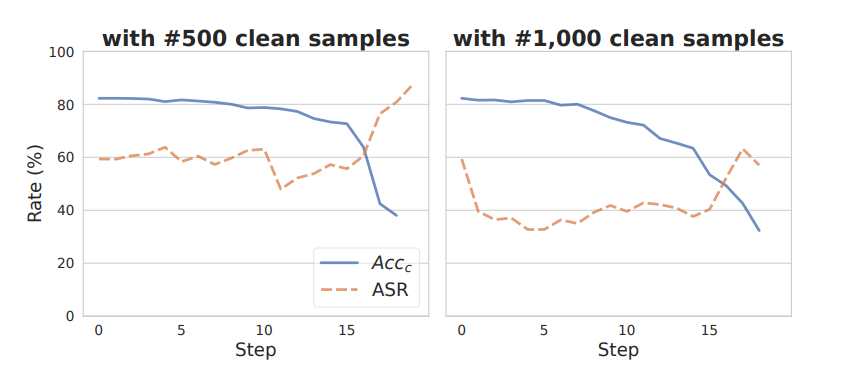
下圖是 HoneypotNet 在 CIFAR10 數(shù)據(jù)集上針對重建神經(jīng)元剪枝(RNP)魯棒性的評估結果:ASR 始終保持在高位,且防御數(shù)據(jù)大小的變化對其影響很小,表明后門注入的穩(wěn)健性,像 RNP 這樣的防御機制難以檢測和修剪,進一步突顯出 HoneypotNet 針對復雜的基于剪枝的防御措施的有效性。
5、總結
本文創(chuàng)新性地提出“以攻為守”的防御范式,通過釋放有毒輸出來對抗模型提取攻擊。其核心實現(xiàn) HoneypotNet 通過使用蜜罐層替換受害者模型的分類頭以生成有毒的概率向量。此外,蜜罐層使用影子模型與影子數(shù)據(jù)集,通過雙層優(yōu)化(BLO)進行微調(diào)。實驗結果證明了 HoneypotNet 在四個數(shù)據(jù)集、五個模型提取攻擊和各種替代模型架構上的有效性。
安全學術圈招募隊友-ing
有興趣加入學術圈的請聯(lián)系?secdr#qq.com
聲明:本文來自安全學術圈,稿件和圖片版權均歸原作者所有。所涉觀點不代表東方安全立場,轉載目的在于傳遞更多信息。如有侵權,請聯(lián)系rhliu@skdlabs.com,我們將及時按原作者或權利人的意愿予以更正。
- 周鴻祎領銜!百所高校+企業(yè)組團亮相ISC.AI 2025“紅衣課堂”
- 港科大發(fā)布大模型越獄攻擊評估基準,覆蓋6大類別37種方法
- 引領智能運維!全新FortiAIOps 3.0重新定義IT運營
- MirageFlow:一種針對Tor的新型帶寬膨脹攻擊
- 英偉達約談事件的制度邏輯與趨勢展望
- 國家互聯(lián)網(wǎng)信息辦公室發(fā)布《國家信息化發(fā)展報告(2024年)》
- 火狐中國終止運營:辦公地無人,用戶賬號數(shù)據(jù)面臨清空
- 25年一直未變!網(wǎng)絡安全永恒的“十大法則”
- 關于征集數(shù)據(jù)安全評估標準化應用實踐案例的通知
- ISC.AI 2025主題前瞻:ALL IN AGENT,全面擁抱智能體時代!