

基于圖網絡分析的加密惡意流量檢測
責編:gltian |2025-06-05 14:19:31
原文標題:Encrypted Malware Traffic Detection via Graph-based Network Analysis
原文作者:Zhuoqun Fu, Mingxuan Liu, Yue Qin, Jia Zhang, Yuan Zou, Qilei Yin, Qi Li and Haixin Duan原文鏈接:https://dl.acm.org/doi/abs/10.1145/3545948.3545983發表平臺:RAID, 2022筆記作者:孫漢林@安全學術圈主編:黃誠@安全學術圈編輯:張貝寧@安全學術圈
1、引言
本文針對加密與規避技術日益復雜所帶來的惡意流量檢測難題,提出了一種基于圖結構的網絡行為建模方法——ST-Graph。該方法在融合傳統流量屬性的基礎上,引入圖表示學習算法,從空間與時間兩個維度對網絡行為特征進行建模,實現多維度特征的融合,從而有效提升檢測性能。實驗結果表明,ST-Graph在兩個真實數據集上均顯著優于現有主流檢測方法,實現了超過99%的檢測精度與召回率。
2、方案設計
本方案由3個部分組成,即流量預處理器、圖表示器和檢測器。
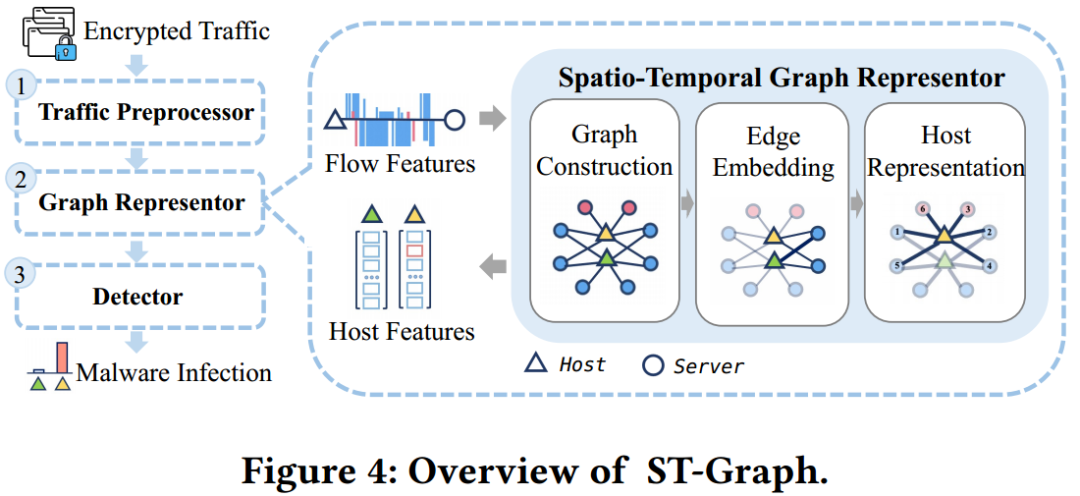
- 流量預處理器:?為解決原始Pcap格式流量數據碎片化、不利于檢測的問題,作者設計了一個預處理模塊,首先通過提取每個數據包的五元組(源IP、源端口、目的IP、目的端口、協議)進行流重組,還原端到端通信過程。隨后,篩選出具有完整TLS握手的TLS流,提取關鍵信息,如TLS版本、支持的加密套件,以及流的統計特征(如數據包數量與字節數)。這些信息不僅提高了數據的可用性,還作為后續圖表示學習的重要輸入,用于輔助惡意流量檢測。
- 圖表示器:?該模塊構建了一個異構圖,用于表達主機與服務器之間的端到端通信關系,結合了時間特征和空間特征。其中,時間特征通過流量統計信息嵌入到節點表示中,空間特征則通過圖的結構體現。基于此,作者設計了一個節點嵌入算法,將這些時空特征轉化為主機的低維向量表示,從而捕捉主機訪問行為之間的相似性。
- 檢測器:?在獲得每個主機的嵌入向量后,系統采用機器學習方法評估其被感染的可能性。作者最終選擇隨機森林(Random Forest, RF)回歸算法作為檢測器,因其在抗過擬合能力和實驗性能方面表現優越。該方法通過多個決策樹的集成預測主機的感染概率,輸出一組可疑主機及其訪問行為信息。
3、ST-Graph構圖算法
ST-Graph通過構建異構圖關聯主機與服務器之間的所有網絡連接,并利用Random Walk[1]算法為每條流生成連接序列,結合概率模型優化邊表示,將每條流以其邊嵌入與流量特征建模;進一步,系統將每個主機的所有訪問按順序整合,生成綜合其網絡結構與行為特征的主機表示。與傳統的圖神經網絡(GNN)或知識圖譜嵌入(KGE)方法相比,ST-Graph避免了大規模參數訓練,采用少量迭代和閉式解優化方式,有效降低了計算復雜度,滿足了實時檢測的需求。
3.1 特征定義
- 空間特征(Spatial Feature):?指主機與目標服務器之間的連接集中性,尤其在同一惡意軟件家族中較為明顯,由于框架復用,同族惡意樣本往往嘗試連接相同的控制服務器,呈現出高相似性。
- 時間特征(Temporal Feature):?指主機在一定時間內的連接順序與行為模式,可幫助重建惡意軟件的感染過程;此外,受固定通信參數影響,感染主機與控制服務器之間的通信在數據包長度和發送間隔方面表現出規律性。
3.2 圖構建
ST-Graph構建了一個主機-服務器二分圖 ,其中節點集 和 分別表示內部主機和外部服務器節點,邊集 表示基于TLS握手的通信連接邊;每條邊附帶時間順序信息 及流特征屬性 。
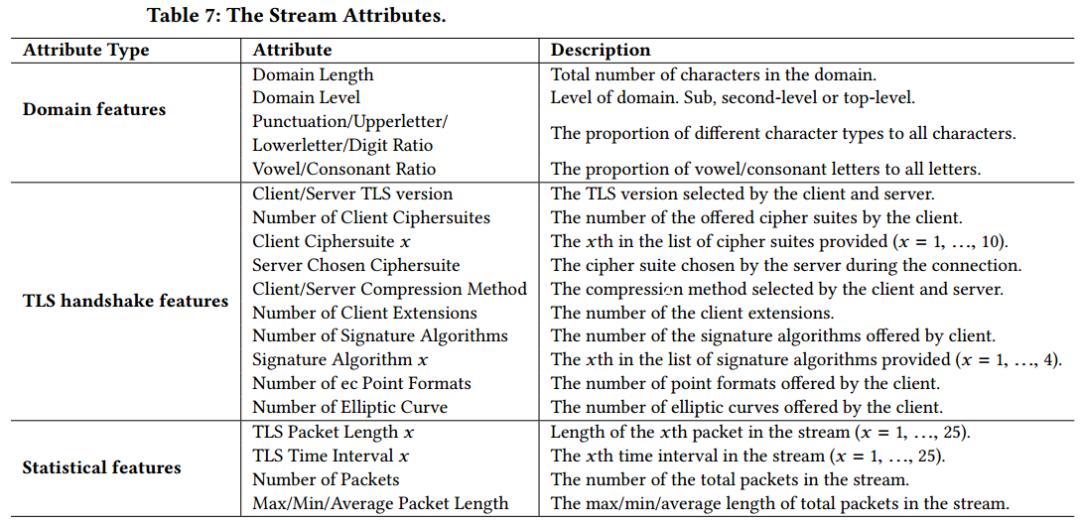
為了全面捕獲加密流量中的惡意行為,作者設計了三類流屬性:1)基于域名的域名生成算法(Domain Generation Algorithms,DGA)識別特征(如字符比例、域名長度等);2)來自TLS握手的加密特征(如TLS版本、密碼套件順序等),揭示潛在的弱加密行為;3)基于側信道的統計特征(如包長、間隔時間等),輔助推斷流量行為模式。這些特征共同用于加強對主機行為的建模,提升加密流量中惡意通信的檢測能力。具體屬性如上表所示。
3.3 邊嵌入
邊嵌入(edge embedding)用于將網絡流表示成數值向量。作者結合兩類特征:一是流的屬性特征 ,保留原始流量信息;二是時空嵌入(spatio-temporal embeddings),反映網絡交互的空間拓撲和訪問的時間順序。
為融合時空嵌入的時間和空間特征,作者提出了一種“區間傾向隨機游走”(Interval-inclined Random Walk)策略,基于圖中邊的連接關系和訪問順序進行游走,傾向選擇時間上相近的邊,以捕捉流生成的時序特性。具體游走時,從當前邊的鄰邊中,按照連接順序差(即兩個邊被同一主機訪問的順序差)以逆距離加權概率選擇下一步,且考慮上兩步游走的狀態,通過超參數p和q控制游走偏向(返回起點或訪問新節點),兼顧廣度優先和深度優先搜索。通過多次隨機游走收集鄰邊集,再利用點積相似度最大化鄰邊與目標邊的相似性,構建時空嵌入向量。采用負采樣和隨機梯度上升優化嵌入向量。最終將流特征和時空嵌入拼接并歸一化,得到完整的邊嵌入表示。該方法高效且兼顧了流的內容和行為時序特征,適用于實時檢測場景。
3.4 主機表示
本文提出了一種基于流的時空特征和訪問重要性加權的信息傳播方法,用于生成主機的向量表示,以輔助檢測感染主機。具體來說,首先通過流的時空嵌入捕捉網絡交互的空間特征和訪問順序的時間特征,形成流的向量表示。然后,針對每個主機,將其相關聯的流信息進行聚合。在聚合過程中,考慮到主機訪問的服務器中存在大量公共服務,部分服務信息對表征主機行為貢獻有限,因此通過訪問頻率和訪問順序兩方面對服務器重要性進行排序和加權,強調那些既常被訪問又較早訪問的服務器流。接著,將流的重要性與主機向量和流嵌入之間的相似度結合,計算主機與流之間的相關性得分。通過最大化所有相關流的聯合相關性得分,利用向量歸一化約束優化主機的表示向量,使其能夠更準確地反映主機的訪問行為特征。
最終,將主機向量輸入到檢測器,以判斷主機是否被感染。
4、實驗設計與評估
實驗涵蓋兩個任務:惡意軟件檢測和惡意軟件家族分類。第一個任務用于區分惡意網絡行為主機和良性主機,第二個任務則進一步識別惡意軟件所屬的具體家族。惡意軟件家族指的是一組具有相似攻擊手法且代碼存在較大重疊的相關程序,將惡意軟件歸類為家族有助于覆蓋其隨時間變化的變種,同時保留家族的特征。
4.1 數據集
本文使用了公開的AndMal2019數據集和自建的EncMal2021數據集,前者包含數千個安卓應用產生的惡意與良性流量,后者基于校園網絡和沙箱環境采集了超過十萬主機的流量數據,其中4.5%為惡意流量。惡意樣本來源于多個知名惡意軟件家族,良性流量通過Alexa排名過濾和沙箱良性樣本緩解采集偏差。數據集在訓練和測試時進行了合理劃分,確保部分測試數據包含新的惡意家族以驗證模型泛化能力。
4.2 實驗結果
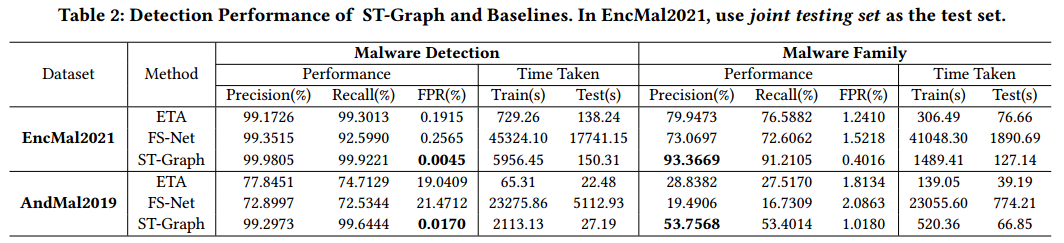
任務一:檢測主機是否被感染
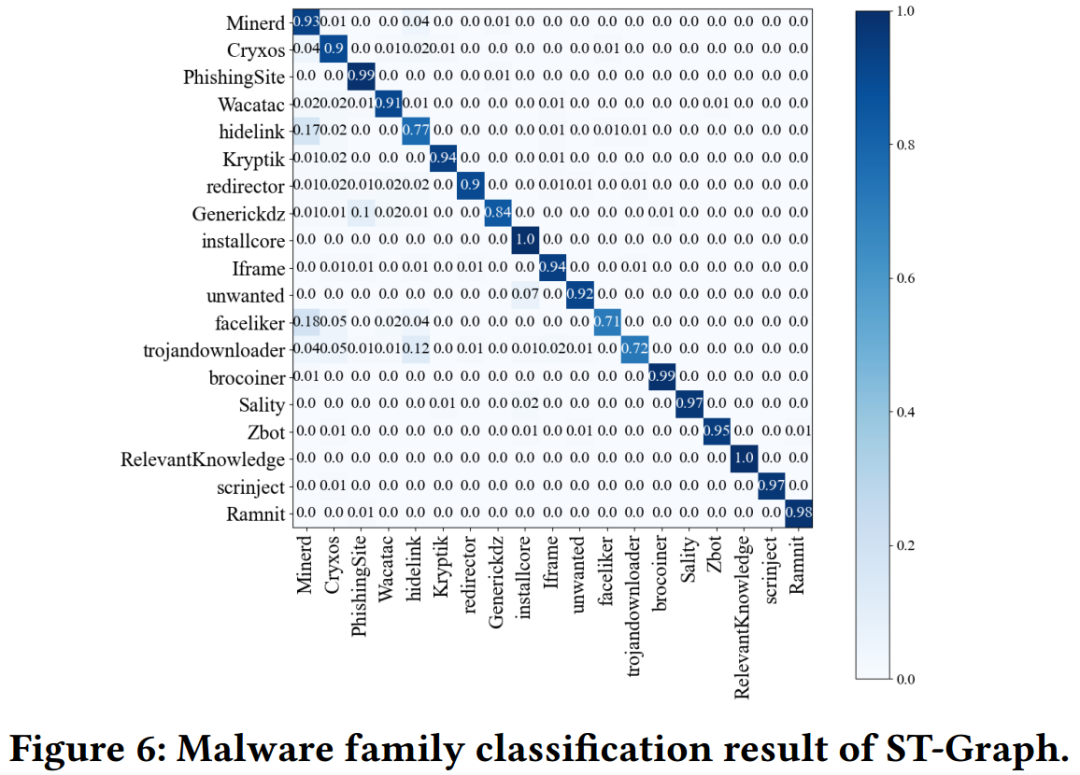
任務二:主機被哪種家族感染
References
[1] Fouss, Francois, et al. “Random-walk computation of similarities between nodes of a graph with application to collaborative recommendation.” IEEE Transactions on knowledge and data engineering 19.3 (2007): 355-369.
安全學術圈招募隊友-ing
有興趣加入學術圈的請聯系?secdr#qq.com