

首次!OpenAI o3模型找到Linux內(nèi)核零日漏洞
責(zé)編:gltian |2025-05-26 11:06:32AI成功找到Linux安全漏洞,還是內(nèi)核級(jí)別的零日漏洞。
剛剛,OpenAI總裁轉(zhuǎn)發(fā)了獨(dú)立研究員Seen Heelan的實(shí)驗(yàn)成果:用o3模型找到了Linux內(nèi)核SMB實(shí)現(xiàn)中的一個(gè)遠(yuǎn)程零日漏洞。
更讓人驚訝的是,整個(gè)過(guò)程中沒(méi)有用到任何復(fù)雜的工具——沒(méi)有腳手架、沒(méi)有智能體框架、沒(méi)有工具調(diào)用,僅僅是o3 API本身。
這個(gè)漏洞被編號(hào)為CVE-2025-37899,是SMB”注銷”命令處理程序中的一個(gè)釋放后使用(use-after-free)漏洞。
據(jù)作者透露,這是首次公開(kāi)討論的由大模型發(fā)現(xiàn)的此類漏洞。

有網(wǎng)友看過(guò)發(fā)現(xiàn)過(guò)程后感嘆,原以為會(huì)有很瘋狂的實(shí)驗(yàn)設(shè)置,但其實(shí)只是把一堆代碼縫到一起,讓o3檢查100次。
希望其他白帽黑客已經(jīng)開(kāi)始像這樣檢查其他關(guān)鍵操作系統(tǒng)了。

OpenAI首席研究官M(fèi)ark Chen表示:像o3這樣的推理模型正開(kāi)始助力深度技術(shù)工作和有意義的科學(xué)發(fā)現(xiàn)。接下來(lái)一年,類似這樣的成果將會(huì)越來(lái)越普遍:

AI不僅找到漏洞,還能輔助修復(fù)
Sean Heelan是一位獨(dú)立研究員,專注于基于大模型的漏洞研究和漏洞利用自動(dòng)化生成。
他原本在手動(dòng)檢查L(zhǎng)inux內(nèi)核的KSMBD(內(nèi)核態(tài)SMB3協(xié)議實(shí)現(xiàn))漏洞,想要暫時(shí)遠(yuǎn)離大模型相關(guān)的工具開(kāi)發(fā)。

但o3發(fā)布后,他忍不住想測(cè)試一下:”既然我手里已經(jīng)有這些漏洞,不如看看o3能不能找到它們?”
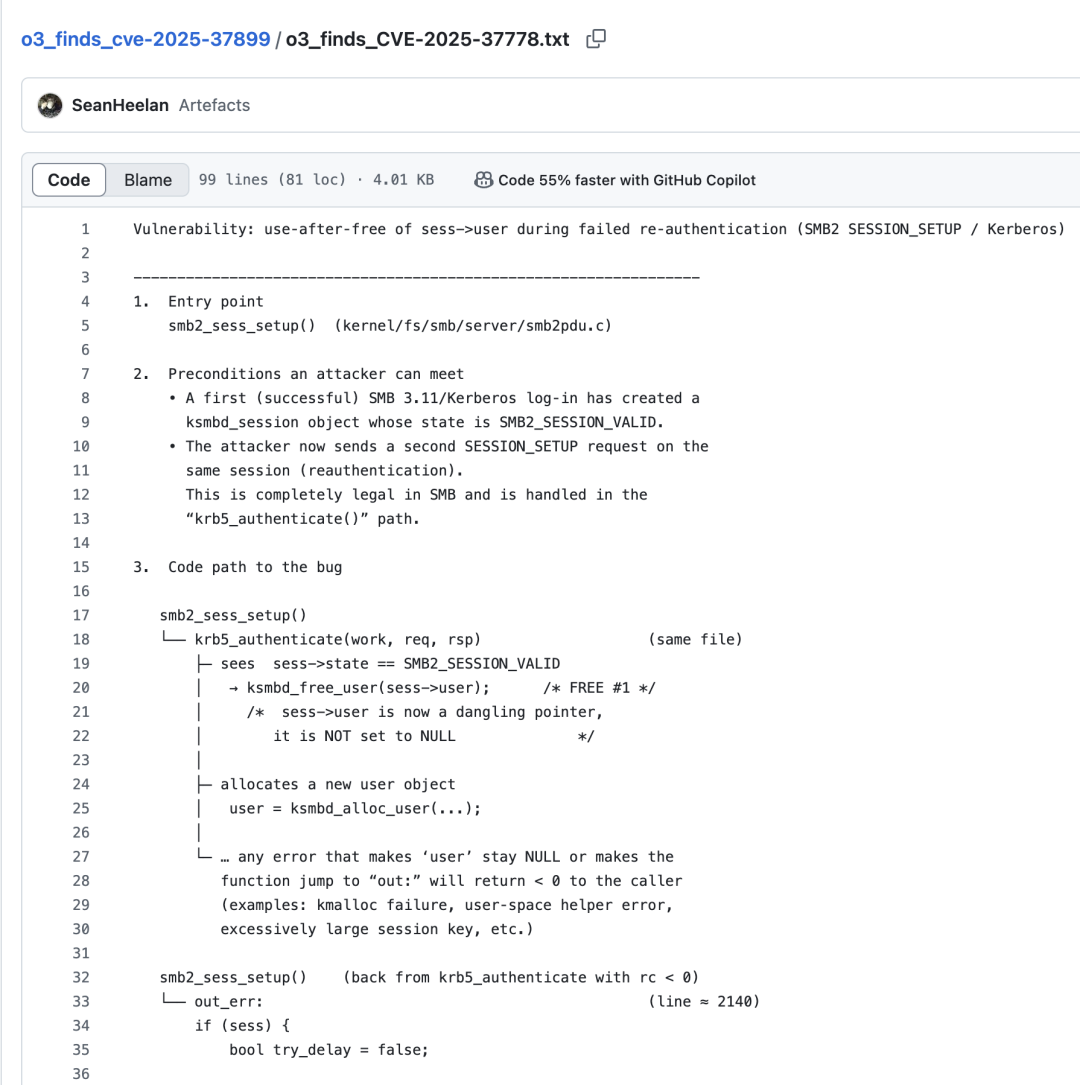
他先用一個(gè)自己手動(dòng)發(fā)現(xiàn)的漏洞CVE-2025-37778作為測(cè)試。這是Kerberos認(rèn)證路徑中的一個(gè)釋放后使用漏洞,是測(cè)試大模型能力很好的基準(zhǔn),因?yàn)椋?/p>
- 它是Linux 內(nèi)核遠(yuǎn)程攻擊面的一部分
- 它并不簡(jiǎn)單,發(fā)現(xiàn)他需要理解如何觸發(fā)特定的會(huì)話狀態(tài)、認(rèn)證函數(shù)的多條執(zhí)行路徑、跨函數(shù)的對(duì)象生命周期管理
- 但它也并非極其復(fù)雜,作者本人可以在10分鐘內(nèi)帶著同時(shí)了解涉及到的約3300行代碼
接下來(lái)開(kāi)始實(shí)驗(yàn)之前,還需要搞清楚一個(gè)問(wèn)題,該給大模型展示哪些代碼?
理想情況當(dāng)然是大模型讀取整個(gè)代碼庫(kù)并輸出結(jié)果,但實(shí)踐中上由于上下文窗口的限制還無(wú)法事先。
最終Heelan為 LLM 提供了“會(huì)話設(shè)置”命令處理程序的代碼,包括它調(diào)用的所有函數(shù)的代碼等等,直到調(diào)用深度達(dá)到3(這是包含推理漏洞所需代碼所需的深度),還包含了命令處理器、連接建立/拆除、請(qǐng)求分發(fā)等完整上下文。
提示詞中告訴o3專門尋找use-after-free漏洞,提供KSMBD架構(gòu)說(shuō)明,強(qiáng)調(diào)要避免誤報(bào),每個(gè)實(shí)驗(yàn)運(yùn)行100次,統(tǒng)計(jì)成功率。
相關(guān)代碼和提示詞已開(kāi)源在GitHub上。
Heelan還按同樣流程測(cè)試了Claude3.7和Claude 3.5作為對(duì)比,結(jié)果o3的表現(xiàn)讓人眼前一亮:
- OpenAI o3: 100次運(yùn)行中成功找到8次漏洞
- Claude 3.7: 100次中找到3次
- Claude 3.5: 100次中一次都沒(méi)找到
此外有意思的的是,o3和Claude的輸出風(fēng)格完全不同。
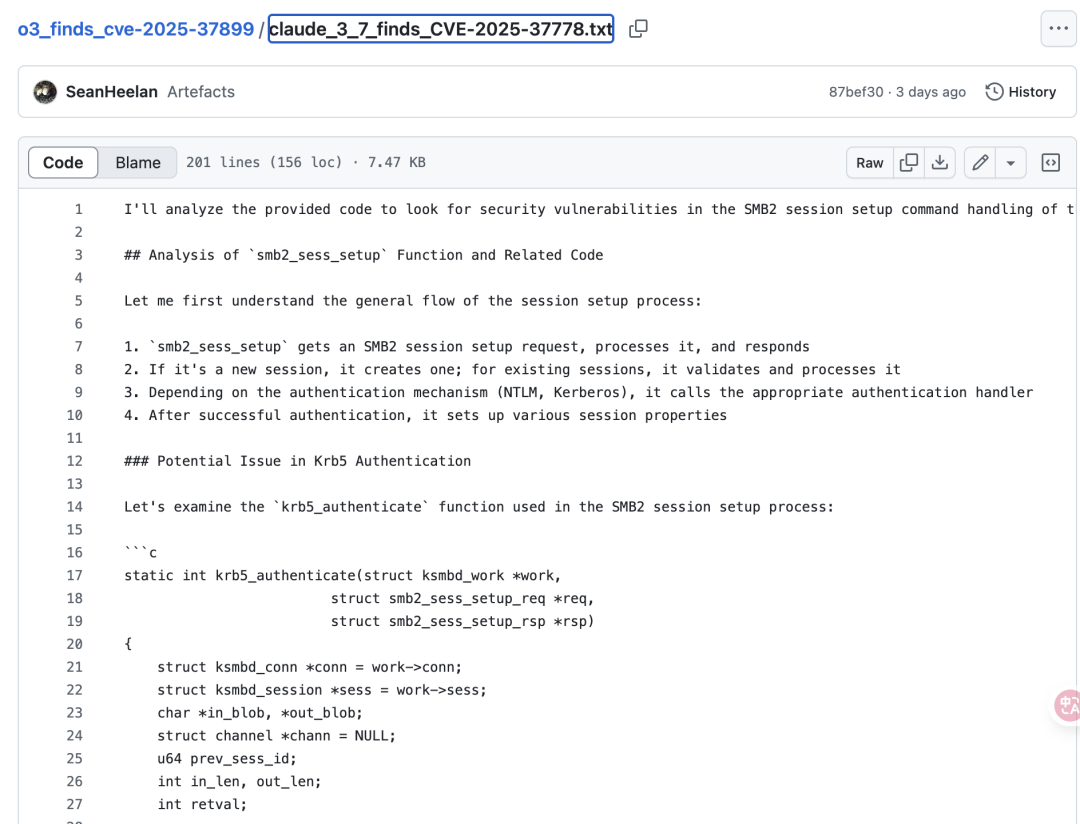
o3生成的像人類寫的漏洞報(bào)告,結(jié)構(gòu)清晰、重點(diǎn)突出
Claude更像思維流或工作日志,細(xì)節(jié)豐富但略顯冗長(zhǎng)。
接下來(lái)發(fā)生的事情更精彩了。
Heelan想測(cè)試o3在更大代碼量下的表現(xiàn),于是給它提供了所有SMB命令處理程序的代碼,約12000行代碼。
雖然找到原始漏洞的成功率降到了1%,性能明顯下降。但在運(yùn)行結(jié)果中,o3報(bào)告了一個(gè)全新的漏洞。
Heelan自己之前也不知道這個(gè)漏洞,它同樣是由于sess->user的釋放造成的,但這次是在會(huì)話注銷處理程序中。

o3自己對(duì)這個(gè)漏洞的解釋如下。
當(dāng)一個(gè)ksmbd工作線程還在執(zhí)行使用sess->user的請(qǐng)求時(shí),另一個(gè)處理同一會(huì)話SMB2 LOGOFF的線程釋放了該結(jié)構(gòu)。沒(méi)有同步機(jī)制保護(hù)該指針,所以第一個(gè)線程會(huì)解引用已釋放的內(nèi)存——這是一個(gè)經(jīng)典的釋放后使用漏洞,會(huì)導(dǎo)致內(nèi)核內(nèi)存損壞和任意代碼執(zhí)行。
更有意思的是,研究員發(fā)現(xiàn)o3不僅能找到漏洞,某些情況下修復(fù)方案比人類更完善。
對(duì)于之前的Kerberos認(rèn)證漏洞,Heelan最初提出的修復(fù)是簡(jiǎn)單地將指針置空:
if (sess->state == SMB2_SESSION_VALID) {ksmbd_free_user(sess->user);sess->user = NULL; // 添加這行}
但o3的報(bào)告中有指出這個(gè)修復(fù)不夠充分,因?yàn)镾MB協(xié)議允許兩個(gè)不同的連接”綁定”到同一個(gè)會(huì)話,在釋放和置空之間的短暫窗口期,另一個(gè)線程仍可能訪問(wèn)這個(gè)指針。
最終Heelan承認(rèn),如果使用o3來(lái)找和修復(fù)原始漏洞,“理論上”會(huì)比自己完成更好。
之所以加上“理論上”的限定,是因?yàn)楝F(xiàn)在AI誤報(bào)的比例有點(diǎn)高,人類很難認(rèn)真仔細(xì)地查看o3的每份報(bào)告。
不過(guò)他也認(rèn)為隨著技術(shù)的發(fā)展,這個(gè)比例只會(huì)越來(lái)越低。
Heelan在報(bào)告結(jié)尾感慨道:
大模型在程序分析技術(shù)的能力空間中,處于一個(gè)比我們見(jiàn)過(guò)的任何東西都更接近人類的位置。考慮到創(chuàng)造力、靈活性和通用性,LLM更像是人類代碼審計(jì)員,而不是符號(hào)執(zhí)行、抽象解釋或模糊測(cè)試。
他特別強(qiáng)調(diào),如果你從事安全研究工作,現(xiàn)在應(yīng)該開(kāi)始密切關(guān)注了:
- 專家級(jí)研究員不會(huì)被取代,反而會(huì)變得更高效
- 對(duì)于10000行以內(nèi)的代碼問(wèn)題,o3有相當(dāng)大的概率能解決或幫助解決
- 雖然仍有約1:50的信噪比問(wèn)題,但這已經(jīng)值得投入時(shí)間和精力
不過(guò)也有人看到了其中的風(fēng)險(xiǎn):
如果壞人利用AI的能力找到類似的漏洞并攻擊系統(tǒng)又如何呢?

聲明:本文來(lái)自量子位,稿件和圖片版權(quán)均歸原作者所有。所涉觀點(diǎn)不代表東方安全立場(chǎng),轉(zhuǎn)載目的在于傳遞更多信息。如有侵權(quán),請(qǐng)聯(lián)系rhliu@skdlabs.com,我們將及時(shí)按原作者或權(quán)利人的意愿予以更正。
- 周鴻祎領(lǐng)銜!百所高校+企業(yè)組團(tuán)亮相ISC.AI 2025“紅衣課堂”
- 港科大發(fā)布大模型越獄攻擊評(píng)估基準(zhǔn),覆蓋6大類別37種方法
- 引領(lǐng)智能運(yùn)維!全新FortiAIOps 3.0重新定義IT運(yùn)營(yíng)
- MirageFlow:一種針對(duì)Tor的新型帶寬膨脹攻擊
- 英偉達(dá)約談事件的制度邏輯與趨勢(shì)展望
- 國(guó)家互聯(lián)網(wǎng)信息辦公室發(fā)布《國(guó)家信息化發(fā)展報(bào)告(2024年)》
- 火狐中國(guó)終止運(yùn)營(yíng):辦公地?zé)o人,用戶賬號(hào)數(shù)據(jù)面臨清空
- 25年一直未變!網(wǎng)絡(luò)安全永恒的“十大法則”
- 關(guān)于征集數(shù)據(jù)安全評(píng)估標(biāo)準(zhǔn)化應(yīng)用實(shí)踐案例的通知
- ISC.AI 2025主題前瞻:ALL IN AGENT,全面擁抱智能體時(shí)代!