

OpenAI、Google等使用的大模型數據集泄露約12000個API密鑰和密碼
責編:gltian |2025-03-04 16:40:09近日,研究人員在用于訓練人工智能模型的Common Crawl數據集中發現了11908個API密鑰、口令以及密碼等敏感信息。

作為全球最大的開源網絡數據集之一,Common Crawl自2008年起持續收集PB級Web數據,并免費向公眾開放。鑒于數據集的龐大體量,許多人工智能項目可能至少在一定程度上依賴這些數字檔案來訓練大型語言模型(LLM),其中包括OpenAI、DeepSeek、Google、Meta、Anthropic和Stability等公司的模型。
盡管Common Crawl的開放共享在很大程度上促進了全球人工智能技術的迅猛發展,但同時也有可能會帶來嚴重的安全風險。
網絡安全公司Truffle Security在對Common Crawl 2024年12月存檔的26.7億個網頁的400TB數據進行掃描時,發現了11908個經過成功驗證的密鑰。這些密鑰被開發人員硬編碼,表明LLM有可能在不安全的代碼基礎上接受了訓練。
值得注意的是,LLM的訓練數據不能直接以原始形式使用,必須經過預處理階段,包括清理和過濾掉不相關的數據、重復項,以及有害或敏感信息等不需要的內容。
研究人員在分析掃描數據后,發現大量Amazon Web Services (AWS)、MailChimp和WalkScore服務的有效API密鑰。

研究人員在Common Crawl數據集中識別出219種不同的密鑰類型,最常見的是MailChimp API密鑰。約1500個Mailchimp API密鑰在前端HTML和 JavaScript中進行了硬編碼。
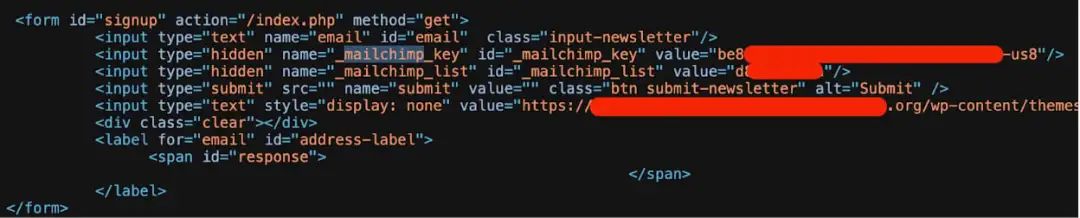
研究人員指出,威脅攻擊者可能會利用上述密鑰繼續進行惡意活動,例如網絡釣魚活動和品牌冒充。不僅如此,密鑰也可能會導致數據泄露。泄露的潛在影響包括:
- 惡意活動:威脅攻擊者可以利用泄露的API密鑰發起釣魚攻擊、品牌冒充或其他惡意活動。
- 數據外泄:密鑰泄露將引發敏感數據如用戶信息、財務數據及醫療記錄被非法獲取的風險。
- 服務濫用:攻擊者濫用密鑰可非法訪問保護服務,進而給服務提供商帶來經濟損失和聲譽風險。
- 高重復使用率:63%泄露密鑰跨頁面重復使用,加劇安全風險,一旦泄露,將波及多個服務和頁面。
Truffle Security在發現這一安全風險后,迅速聯系了受影響的供應商,并協助他們撤銷和更換密鑰。目前來看,盡管LLM訓練數據在預處理階段會進行清理和過濾,但完全去除敏感信息仍然具有挑戰性。
文章來源 | bleeping computer